Essence
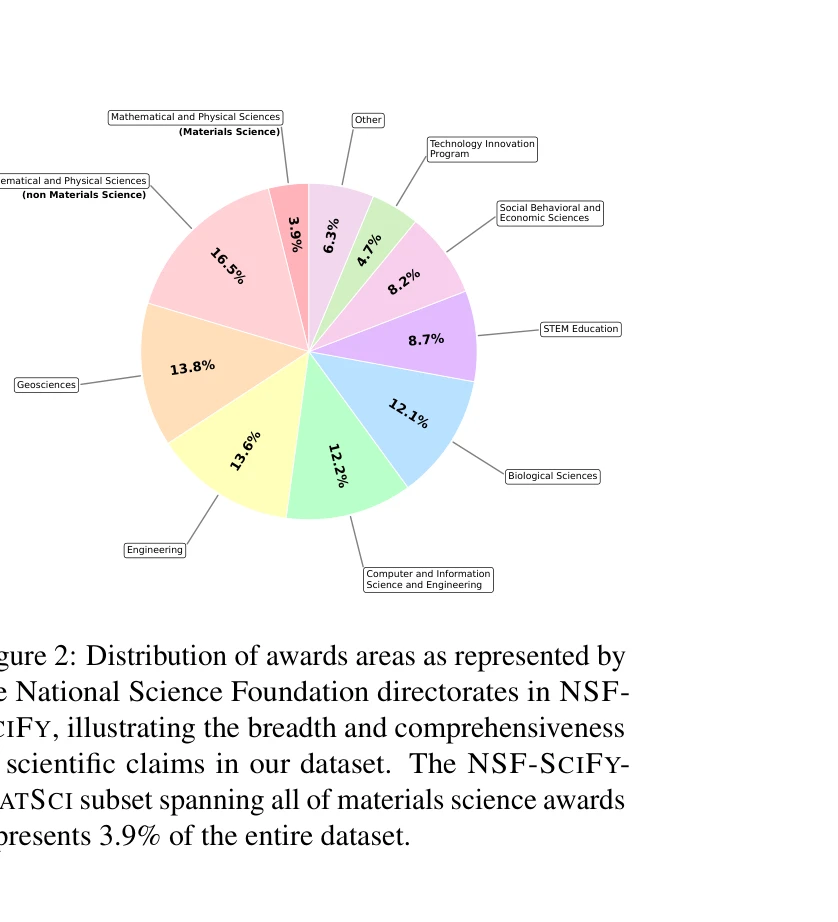
NSF 주요 지원 분야별 분포: 재료과학(3.9%), 수학물리과학(16.5%), 지구과학(13.8%) 등
NSF(미국 국립과학재단) 지원금 데이터베이스에서 과학적 주장(scientific claims)과 연구 제안(investigation proposals)을 대규모로 추출한 데이터셋 NSF-SCIFY를 제시한다. 1970년부터 2024년까지 50년간 400K개 이상의 지원금 초록에서 추정 280만 개의 과학적 주장을 추출하여 현재까지 가장 큰 규모의 과학적 주장 데이터셋을 구축했다.
