저자: Zekun Li, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim, Sungyoung Ji, Byungju Lee, Xifeng Yan, Linda Ruth Petzold, Stephen D. Wilson, Woosang Lim, William Yang Wang | 날짜: 2024 | DOI: N/A
Essence
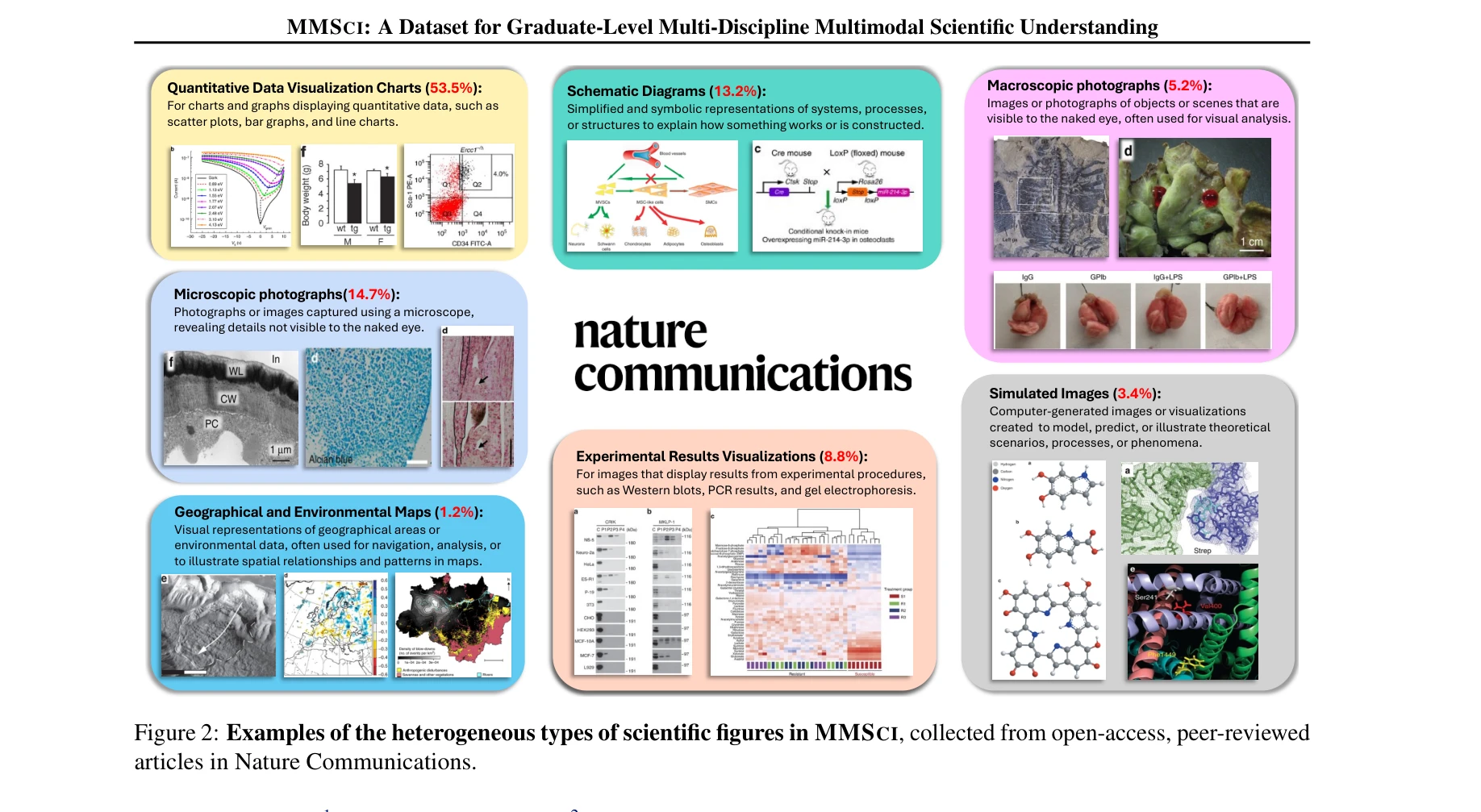
그림 1: MMSCI 데이터셋의 상위 20개 과학 분야별 논문 수와 이미지 수
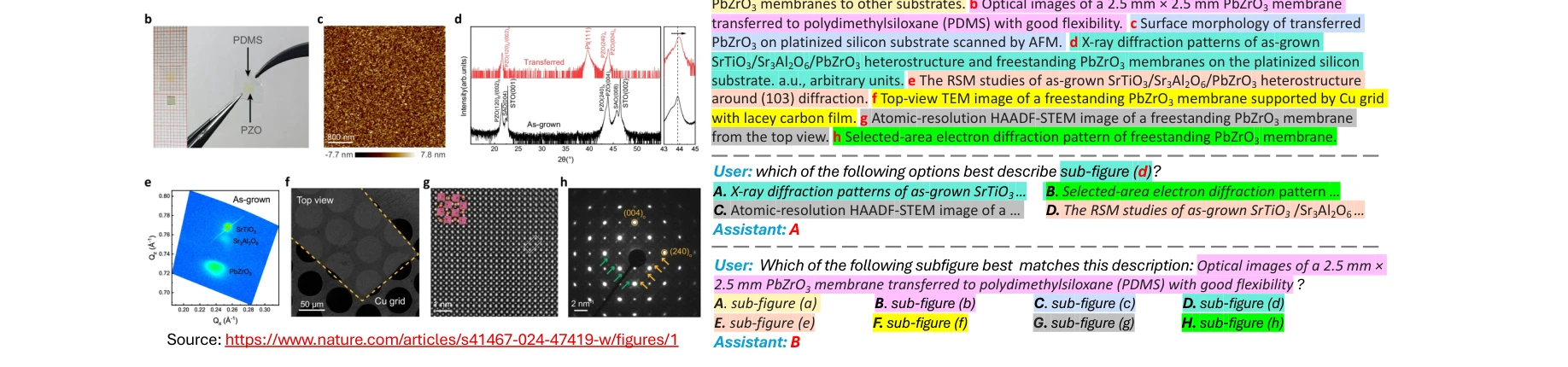
본 논문은 Nature Communications의 동료평가 논문 131,393개로부터 742,273개의 이미지를 수집하여, 72개 학문 분야의 대학원 수준 복잡한 과학 시각화를 이해하기 위한 대규모 멀티모달 데이터셋(MMSCI)을 제시한다. 이를 통해 19개 언어비전모델(Large Vision Language Models, LVLMs)을 평가하며, 미세 조정 및 사전 학습을 통해 모델 성능을 향상시킬 수 있음을 보여준다.
Evaluation
총평: MMSCI는 과학 분야의 복잡한 멀티모달 이해를 다루는 대규모 고품질 데이터셋으로, 기존 차트 중심 벤치마크의 한계를 극복하고 다양한 도메인의 graduate-level 시각화 해석을 가능하게 한다. 실제 미세 조정과 사전 학습을 통한 성능 향상을 입증함으로써 과학 AI 어시스턴트 개발의 중요한 기반을 제공하며, 특히 도메인 전문가 수준의 모델 성능 달성은 실무적 가치를 입증한다.