저자: Ran Xu, Yuchen Zhuang, Yishan Zhong, Yue Yu, Zifeng Wang, Xiangru Tang, Hang Wu, May D. Wang, Peifeng Ruan, Donghan Yang, Tao Wang, Guanghua Xiao, Xin Liu, Carl Yang, Yang Xie, Wenqi Shi | 날짜: 2025-06-04 | DOI: 미제공
Essence
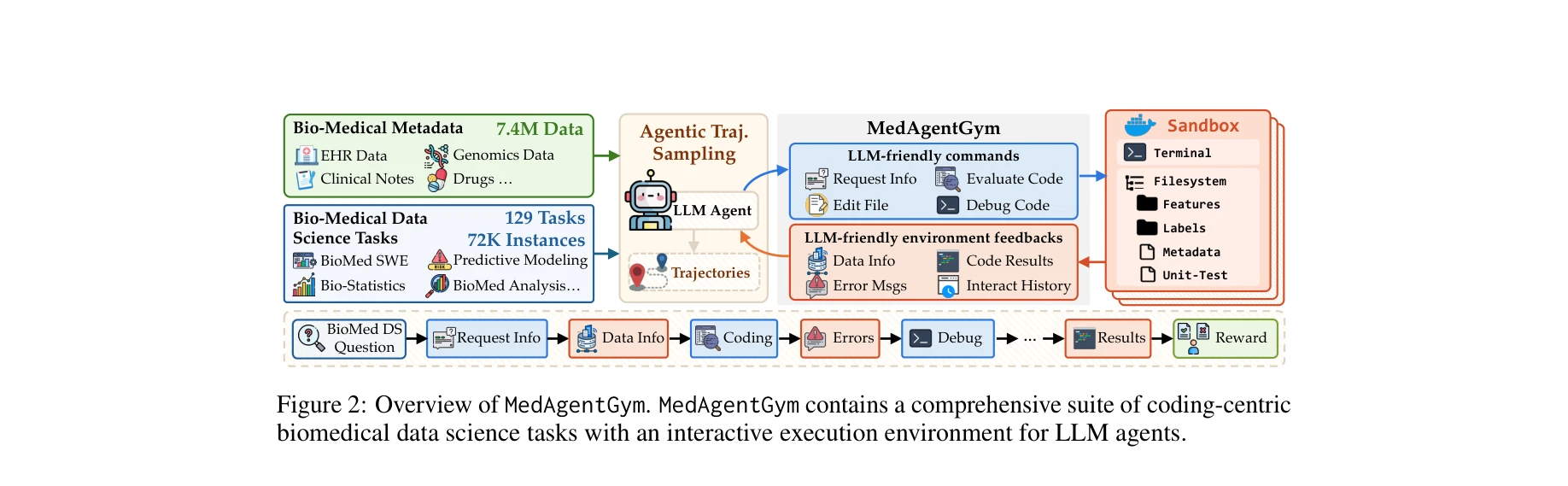
Figure 1: (a) MedAgentGym의 과제별 성능과 (b) 전체 리더보드 평가. 상용 LLM과 오픈소스 LLM 간 상당한 성능 격차를 시각화함
본 논문은 생의학 데이터 과학(biomedical data science)에서 코드 기반 추론 능력을 강화하기 위한 확장 가능한 LLM 에이전트 훈련 환경인 MedAgentGym을 제시한다. 72,413개의 과제 인스턴스와 실행 가능한 샌드박스 환경을 통해 오픈소스 LLM들의 생의학 코딩 역량을 대폭 향상시킬 수 있음을 입증한다.
Evaluation
총평: MedAgentGym은 생의학 데이터 과학 분야에서 코드 기반 추론을 위한 최초의 포괄적이고 실행 가능한 훈련 환경으로, 대규모 통합 벤치마크, 효과적인 RL 훈련 방법론, 그리고 공개된 리소스를 통해 오픈소스 LLM의 의료 도메인 적응에