Achievement

- 정확도 대폭 개선: FCGEC 데이터셋에서 기준 모델 대비 정확도(Precision) +18.2점 향상, F0.5 +5.8점 개선으로 SOTA 수준 달성
- 재현율 유지: 높은 정확도 개선에도 불구하고 재현율(Recall)을 일정하게 유지하여 실용성 확보
- 경량성과 효율성: 소규모 파라미터와 제한된 훈련 데이터(천 단위)로도 우수한 성능 달성, ChatGPT 같은 블랙박스 시스템의 과도한 수정 완화에 활용 가능
저자: Yixuan Wang, Baoxin Wang, Yijun Liu, Dayong Wu, Wanxiang Che | 날짜: 2024 | DOI: 미제공
중국어 문법 오류 수정(CGEC) 시스템의 과도한 수정(over-correction) 문제를 해결하기 위해, 기존 GEC 시스템의 출력을 입력받아 직접 재작성하는 경량의 언어모델 기반 필터링 모델을 제안한다.
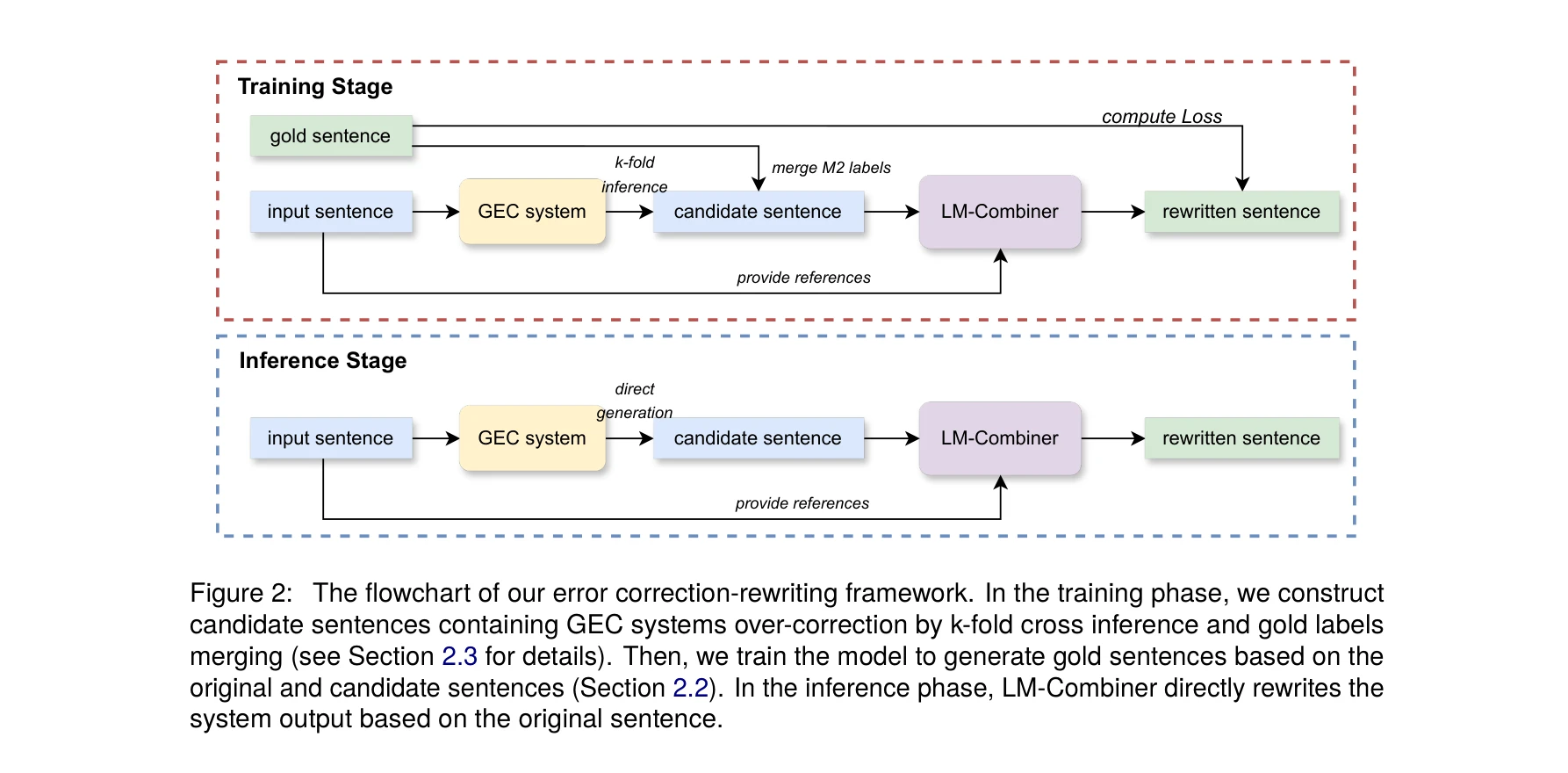
총평: 과도한 수정 문제를 효과적으로 해결하기 위해 재작성 모델이라는 실용적인 접근을 제시하며, K-fold 교차 추론이라는 창의적 데이터 구성 방법으로 인해 학술적 가치가 있다. 다만 평가 범위의 확대와 더 엄밀한 일반화 검증이 필요하다.