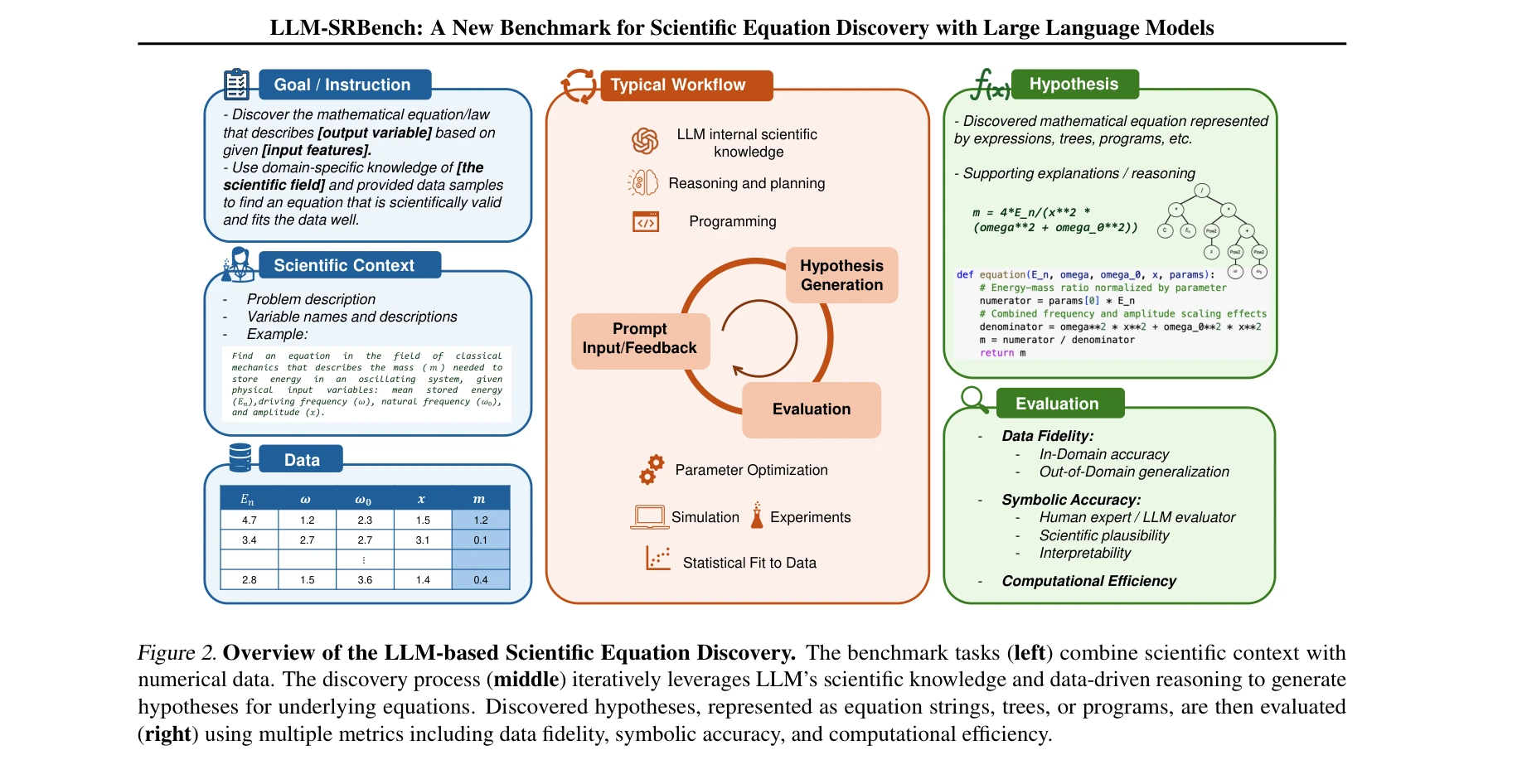
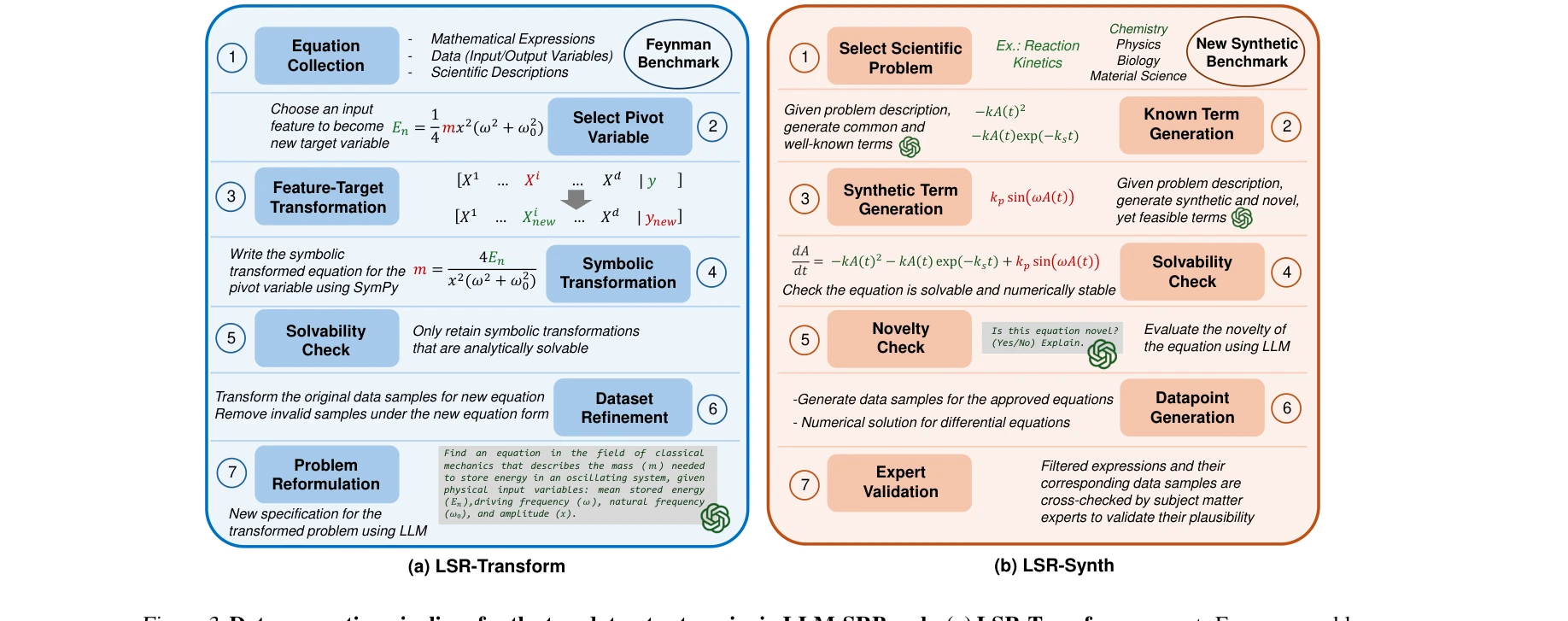
Essence
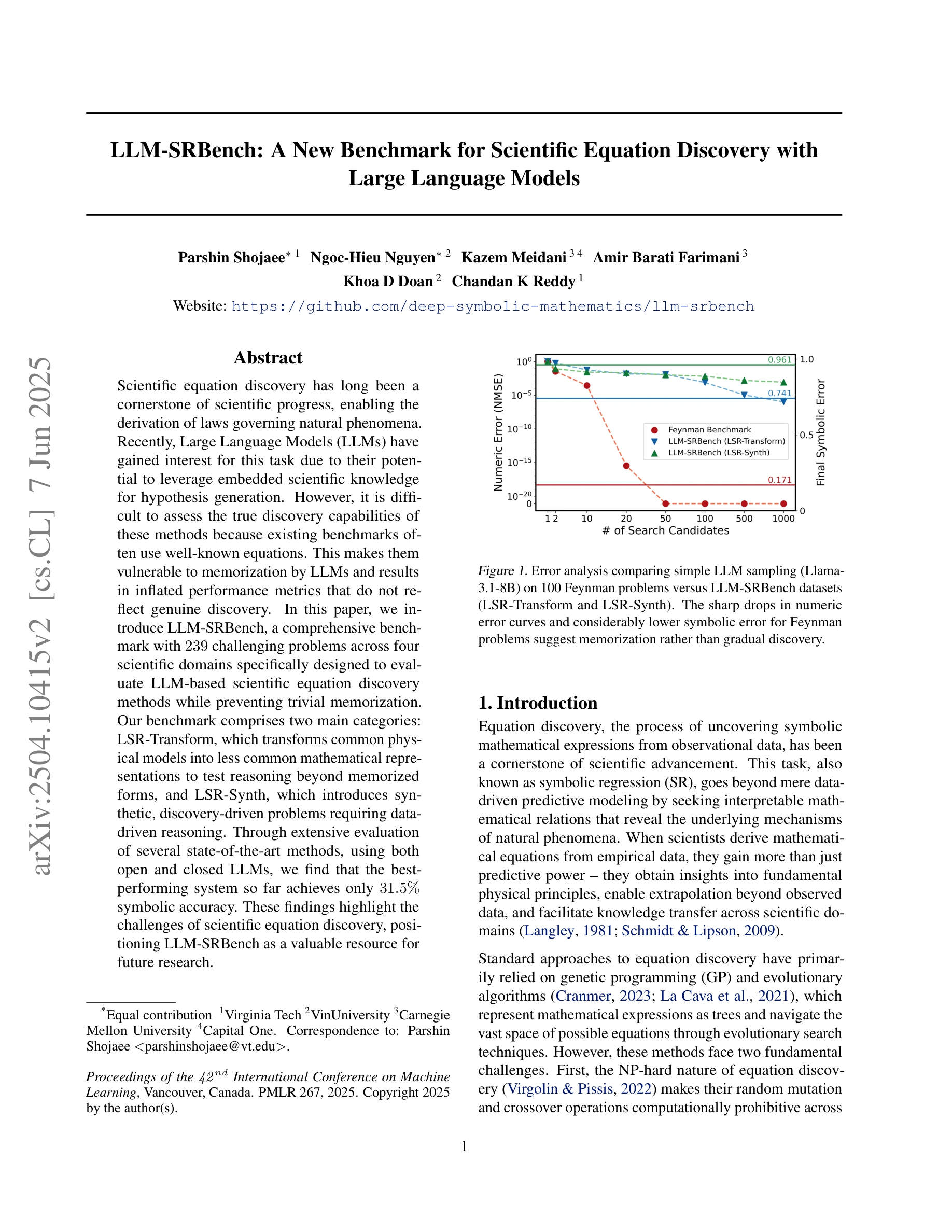
Figure 1. Feynman 문제와 LLM-SRBench 데이터셋(LSR-Transform, LSR-Synth)에서 단순 LLM 샘플링(Llama-3.1-8B)의 오차 분석. Feynman 문제에서 수치 오차 곡선의 급격한 하강과 낮은 기호 오차는 실제 발견보다 암기를 시사함.
본 논문은 대규모 언어 모델(LLM) 기반 과학 방정식 발견의 진정한 능력을 평가하기 위해 암기를 방지하는 종합적 벤치마크 LLM-SRBench를 제안한다. 4개 과학 분야에서 239개 도전 문제로 구성되어 있으며, 최고 성능 모델도 31.5% 기호 정확도에 불과함을 보여준다.