How
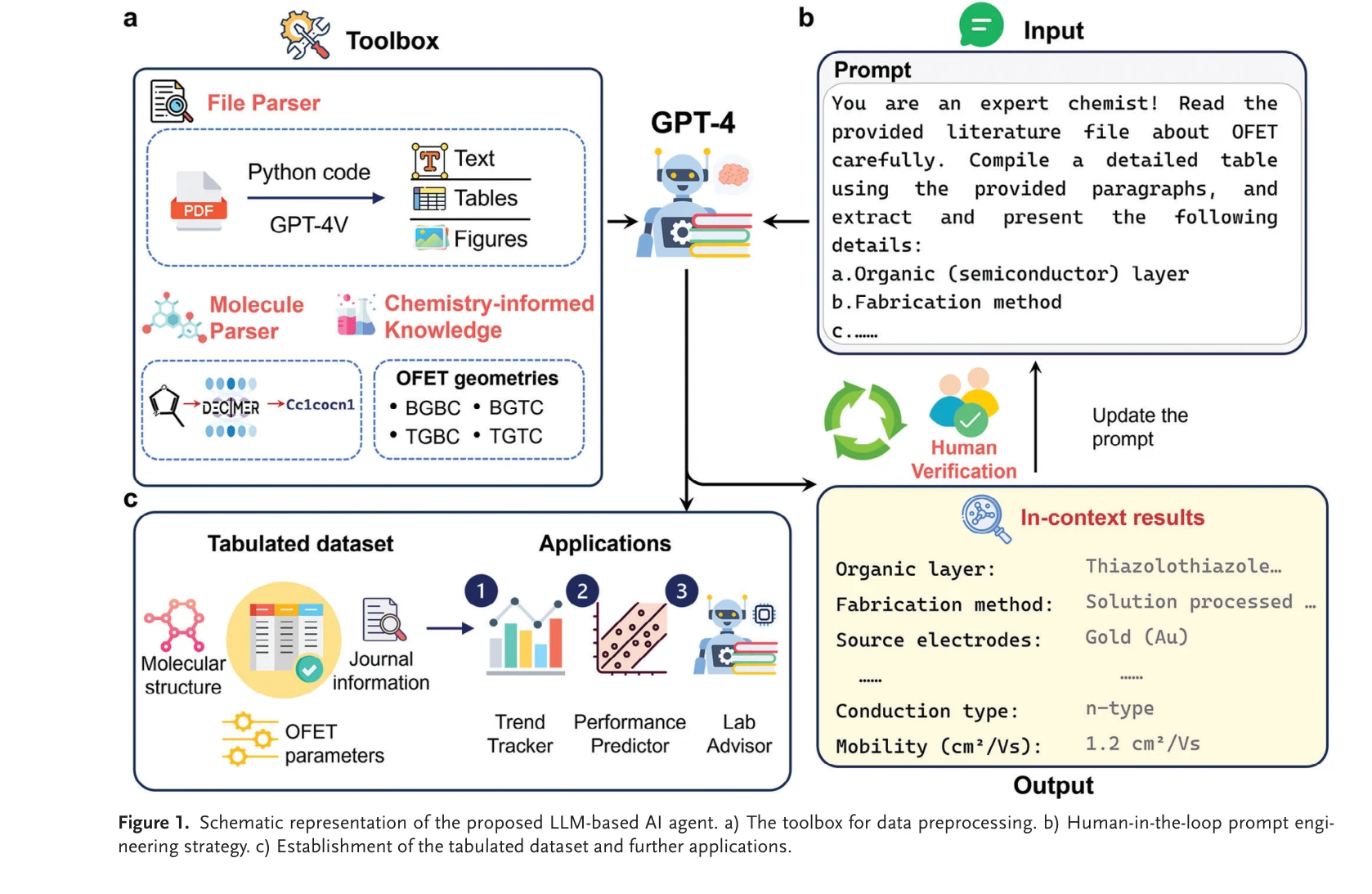
LLM 기반 AI 에이전트의 체계적 표현: a) 데이터 전처리 도구 상자, b) Human-in-the-loop 프롬프트 엔지니어링 전략, c) 표준화 데이터셋 구축 및 후속 응용
핵심 방법론:
- PDF 파일 파싱: Python 코드와 GPT-4 Vision을 활용하여 PDF를 텍스트, 표, 이미지로 분해
- 멀티모달 데이터 처리:
- 텍스트 및 표 데이터: GPT-4 자연어 처리
- 분자 구조 이미지: DECIMER 도구로 SMILES 형식으로 변환
- 소자 구조 다이어그램: GPT-4 Vision으로 기하학적 파라미터 추출
- 프롬프트 엔지니어링:
- 초기 프롬프트 설계 후 반복적 평가·개선
- 일반적인 OFET 구성(BGBC, BGTC, TGBC, TGTC) 등 화학 도메인 지식 통합
- GPT-4의 128,000 토큰 처리 용량 활용으로 전체 논문 컨텍스트 유지
- 성능 평가: 14개 파라미터 약 10,000개에 대해 수동 검증으로 True Positive, False Positive, False Negative 분류
- 머신러닝 모델: XGBoost 기반 성능 예측 모델 구축 및 SHAP(SHapley Additive exPlanations) 분석으로 중요 인자 해석
- Lab Advisor: 데이터베이스 쿼리와 GPT-4 추론을 결합하여 맞춤형 실험 제안 생성