Achievement
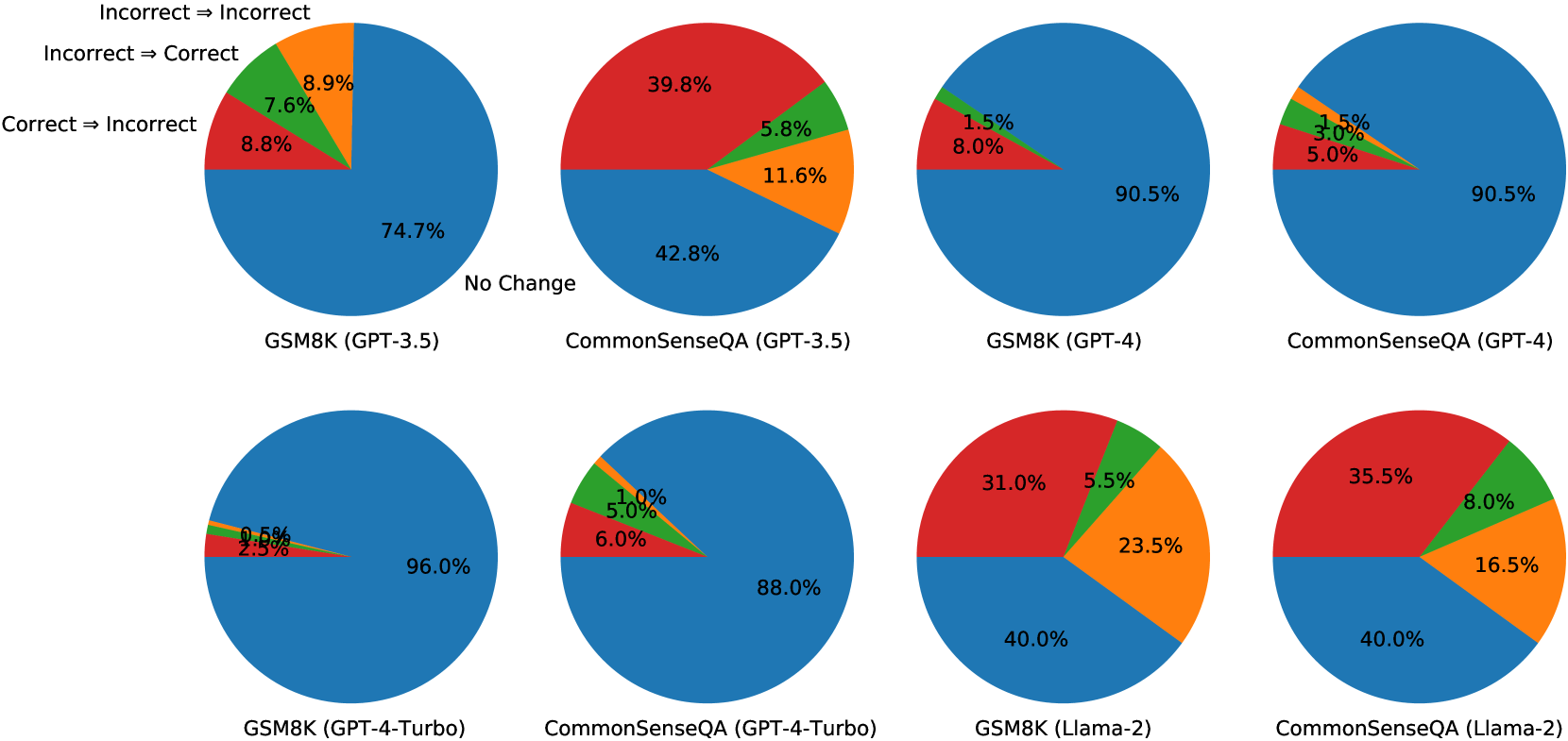
두 라운드의 자기 수정 후 답변 변화 분석: 변화 없음, 올바른→잘못된, 잘못된→올바른 범주별 비율
- 오라클 라벨 문제: GSM8K, CommonSenseQA, HotpotQA에서 오라클 라벨을 사용한 자기 수정은 상당한 성능 개선(7-15%)을 보이지만, 외부 피드백 없는 내재적 자기 수정에서는 모든 모델과 데이터셋에서 성능 저하 관찰 (GPT-3.5: GSM8K 75.9%→75.1%, CommonSenseQA 75.8%→38.1%; GPT-4: 95.5%→91.5%, 82.0%→79.5%).
- 다중 에이전트 토론의 한계: 여러 LLM 인스턴스가 서로의 답을 비판하는 다중 에이전트 토론(Multi-Agent Debate)은 동등한 응답 수를 기준으로 자기일관성(self-consistency)보다 나은 성능을 보이지 못함.
- 프롬프트 설계 문제: 일부 기존 연구의 개선 효과는 초기 응답 생성 시 부최적(sub-optimal) 프롬프트를 사용한 것에서 비롯됨. 피드백을 초기 지시사항에 통합하면 자기 수정을 사용한 것보다 더 좋은 결과를 얻음.