Essence

자기-강화(self-reinforcement)를 통해 암묵적 규범을 점진적으로 증폭시켜 모델이 명시적으로 표현하도록 유도하는 개념적 틀
대규모 언어모델(LLM)이 내재된 편향을 진단 도구로 활용하여 과학과 사회의 "불문율(unwritten code)" — 암묵적 고정관념, 휴리스틱, 암수정인 규범 — 을 명시적으로 드러내고 비판 대상으로 만들 수 있다는 주장.
저자: Honglin Bao, Siyang Wu, Jiwoong Choi, Yingrong Mao, James A. Evans (University of Chicago) | 날짜: 2025 | DOI: arXiv:2505.18942
자기-강화(self-reinforcement)를 통해 암묵적 규범을 점진적으로 증폭시켜 모델이 명시적으로 표현하도록 유도하는 개념적 틀
대규모 언어모델(LLM)이 내재된 편향을 진단 도구로 활용하여 과학과 사회의 "불문율(unwritten code)" — 암묵적 고정관념, 휴리스틱, 암수정인 규범 — 을 명시적으로 드러내고 비판 대상으로 만들 수 있다는 주장.
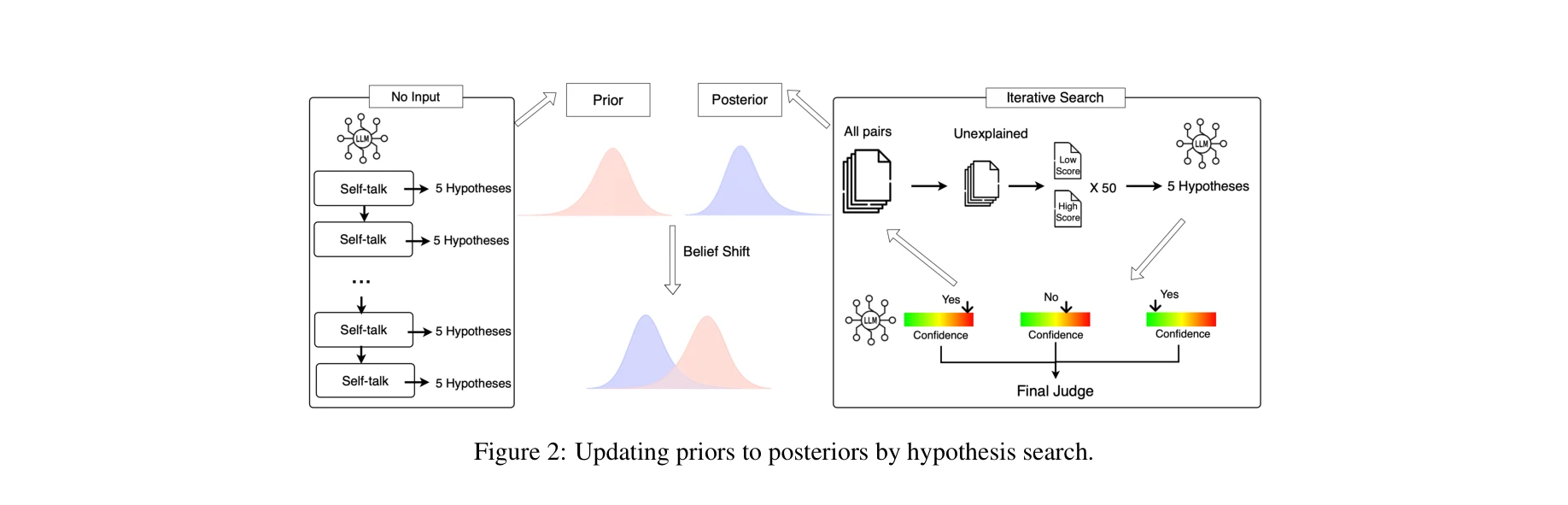
가설 탐색을 통한 선험적 신념에서 사후적 신념으로의 전환 과정
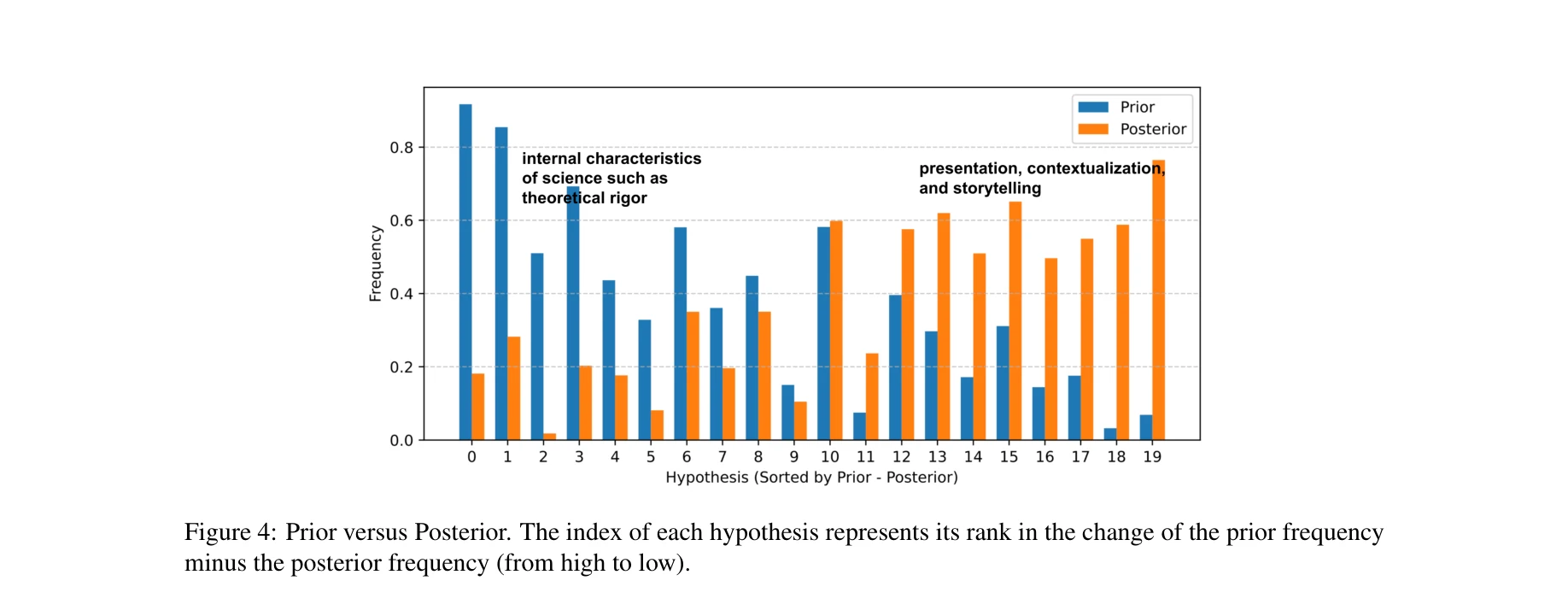
선험적 신념 대비 사후적 신념: 각 가설의 지수는 선험 빈도 변화의 순위를 나타냄
방법론적 특징:
후속 연구:
총평: 이 논문은 LLM의 편향을 사회 진단의 도구로 재해석하는 혁신적 관점을 제시하며, 과학 평가의 암묵적 기준을 최초로 규명한 엄밀한 실증 연구다. 다만 인과성 확립, 실제 제도 개선 효과 검증, 그리고 이러한 "불문율" 공개의 윤리적 함의에 대한 더 깊은 성찰이 필요하다.