Achievement
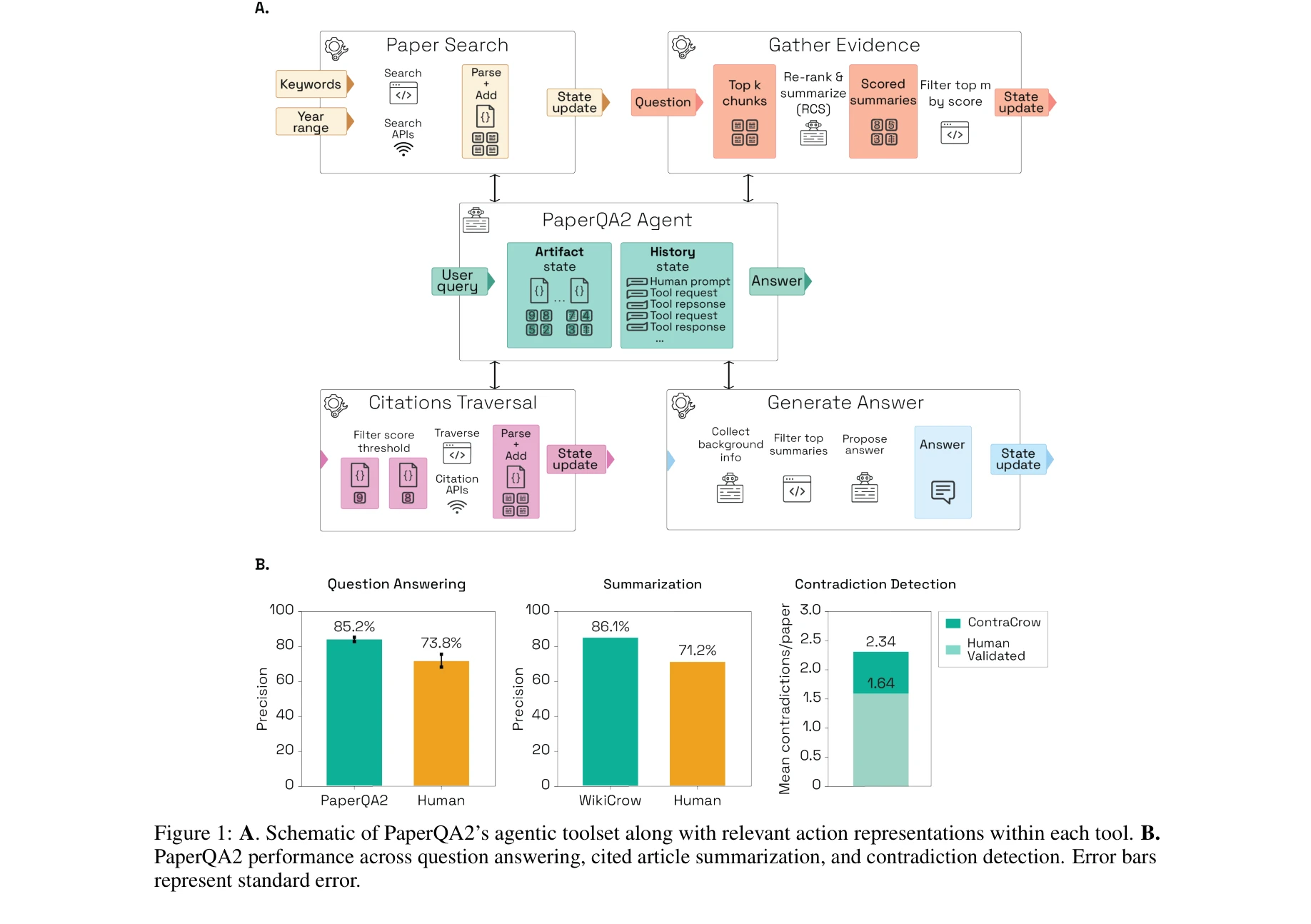
PaperQA2의 아키텍처와 핵심 성능 지표
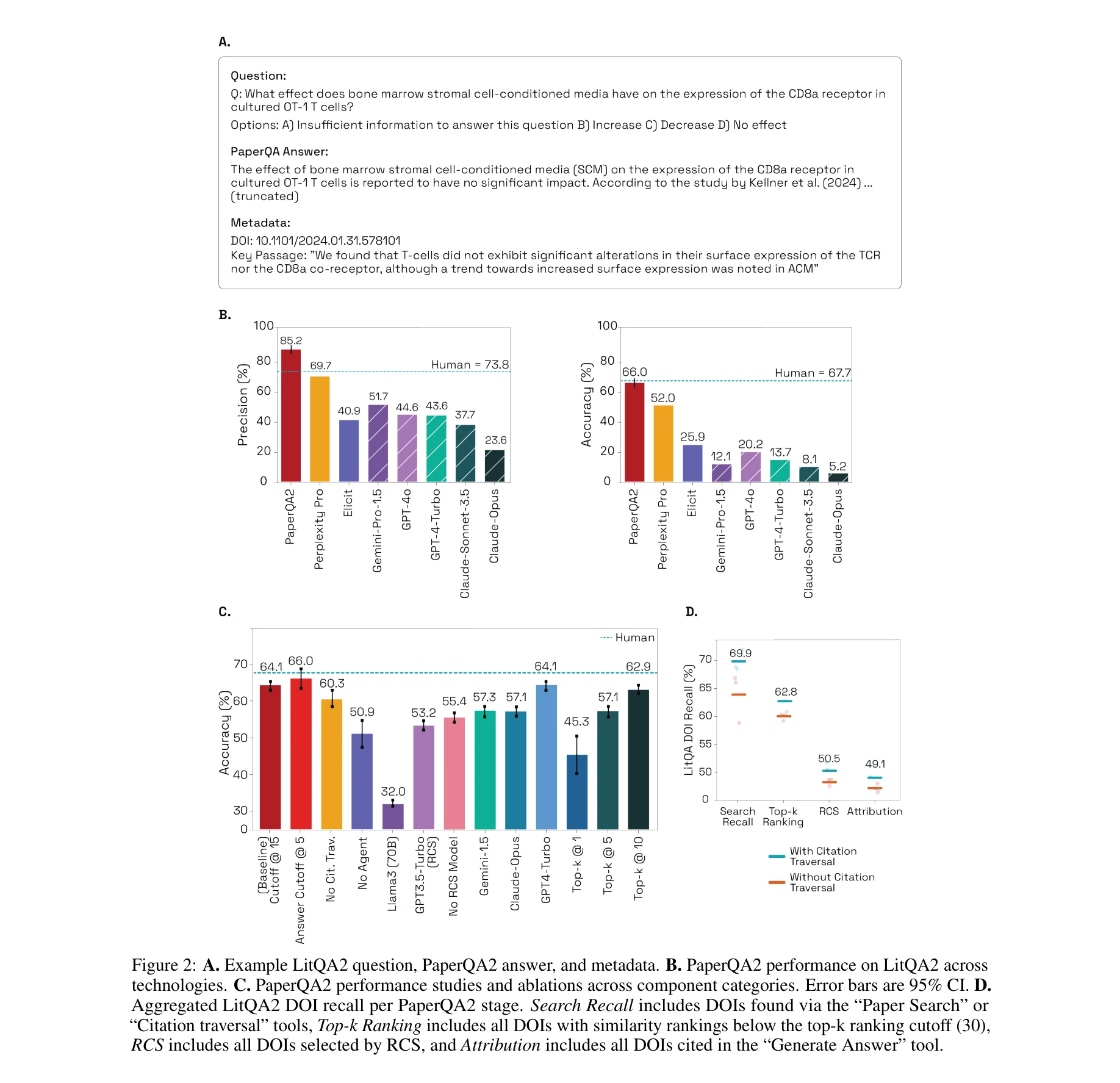
- 문헌 검색 작업(Question Answering): PaperQA2는 LitQA2에서 85.2% ± 1.1%의 정밀도(precision)를 달성하여 박사 수준 인간 전문가의 73.8% ± 9.6%를 초월하는 초인간 성능 달성 (p = 0.0036). 정확도(accuracy)는 66.0% ± 1.2%로 인간의 67.7% ± 11.9%와 통계적으로 유의미한 차이 없음.
- 인용 요약 작업(Cited Summarization): Wikipedia 스타일의 과학 주제 요약을 작성하여 기존 인간 작성 Wikipedia 기사보다 유의미하게 높은 정확도 달성.
- 모순 탐지 작업(Contradiction Detection): 생물학 논문에서 평균 2.34 ± 1.99개의 모순을 식별하며, 이 중 70%가 인간 전문가에 의해 검증됨. 기존 논문의 ZNF804A rs1344706 유전자형과 정신분열증의 관계에 대한 상충하는 주장들을 자동으로 발견.