Essence
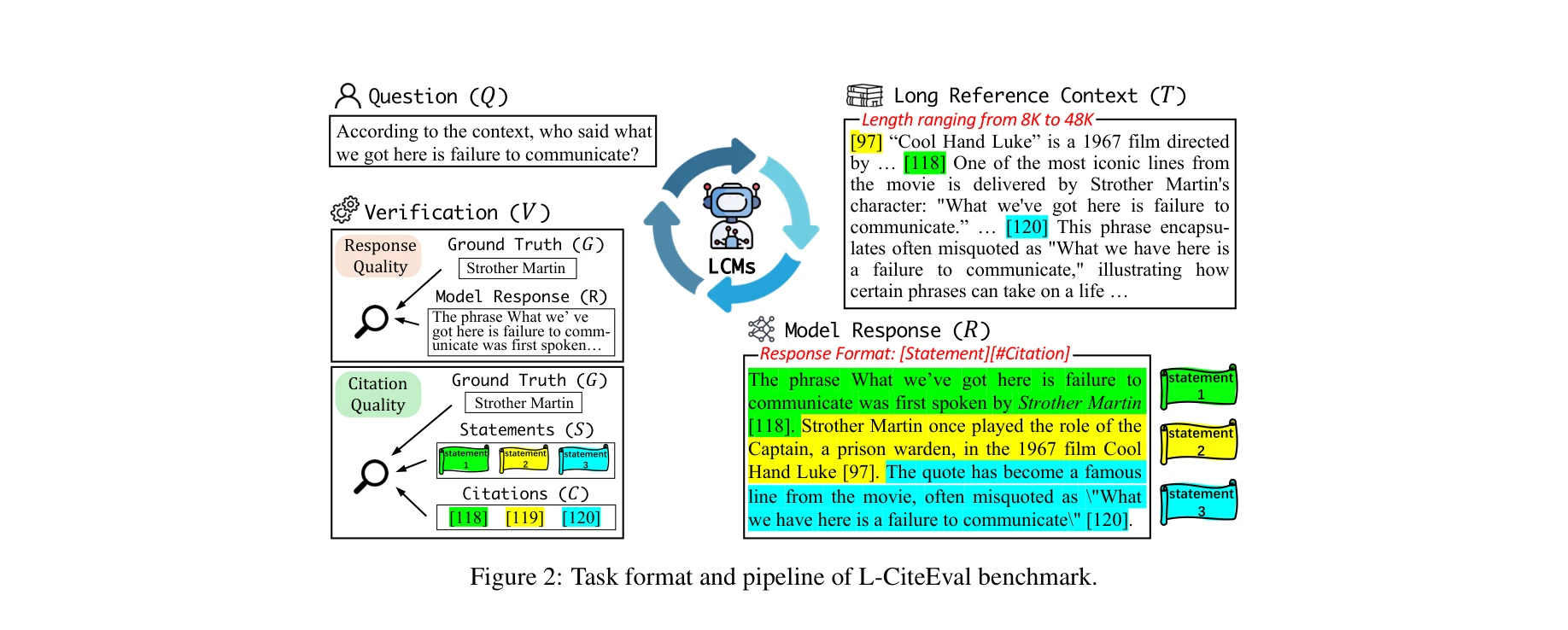
L-CiteEval 벤치마크의 작업 형식 및 파이프라인: 장문 맥락이 주어졌을 때 모델이 답변과 함께 인용(citation)을 생성하도록 요구
장문맥 언어모델(Long-Context Models, LCMs)이 실제로 주어진 맥락을 활용하여 응답하는지 평가하는 종합 벤치마크 L-CiteEval을 제시하며, 자동화된 평가를 통해 모델의 생성 품질뿐 아니라 인용 정확도(citation accuracy)를 동시에 측정한다.
저자: Zecheng Tang, Keyan Zhou, Juntao Li, Baibei Ji, Jianye Hou, Min Zhang | 날짜: 2024 | DOI: 제공 안함
L-CiteEval 벤치마크의 작업 형식 및 파이프라인: 장문 맥락이 주어졌을 때 모델이 답변과 함께 인용(citation)을 생성하도록 요구
장문맥 언어모델(Long-Context Models, LCMs)이 실제로 주어진 맥락을 활용하여 응답하는지 평가하는 종합 벤치마크 L-CiteEval을 제시하며, 자동화된 평가를 통해 모델의 생성 품질뿐 아니라 인용 정확도(citation accuracy)를 동시에 측정한다.
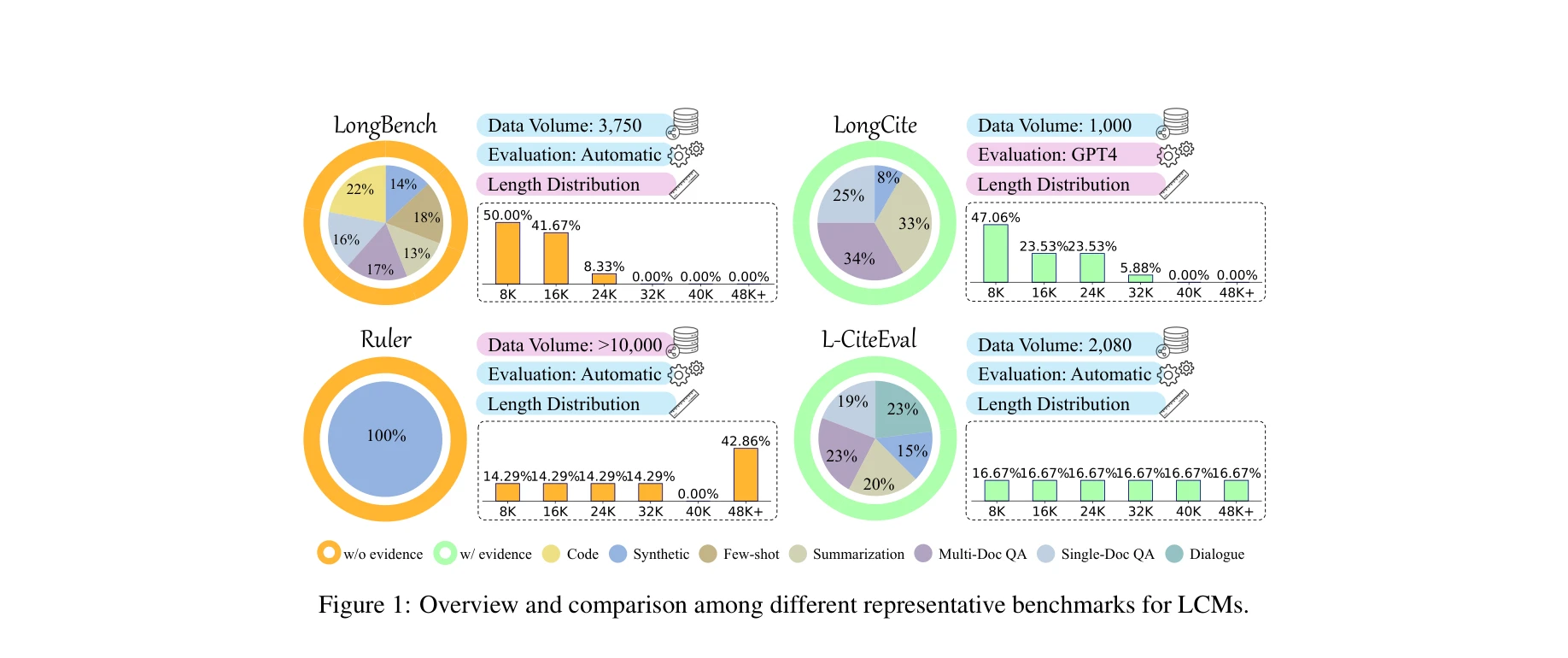
기존 장문맥 벤치마크(LongBench, Ruler, LongCite)와 L-CiteEval의 비교: 데이터 규모, 평가 방식, 작업 분포
응답 형식: [statement₁][citation₁] [statement₂][citation₂] 형태로 각 문장 뒤에 인용 청크 인덱스 붙임
총평: L-CiteEval은 LCM의 맥락 활용도를 자동화된 방식으로 평가하는 첫 대규모 벤치마크로서, 개폐형 모델 간의 현저한 차이를 정량적으로 입증했다는 점에서 중요한 기여를 한다. 다만 인용 청크 크기 설정, 인간 평가 검증, 작업 다양성 확대 측면에서 개선의 여지가 있으며, 자동 메트릭의 신뢰성 강화와 모델 개선 기법 개발이 향후 과제이다.