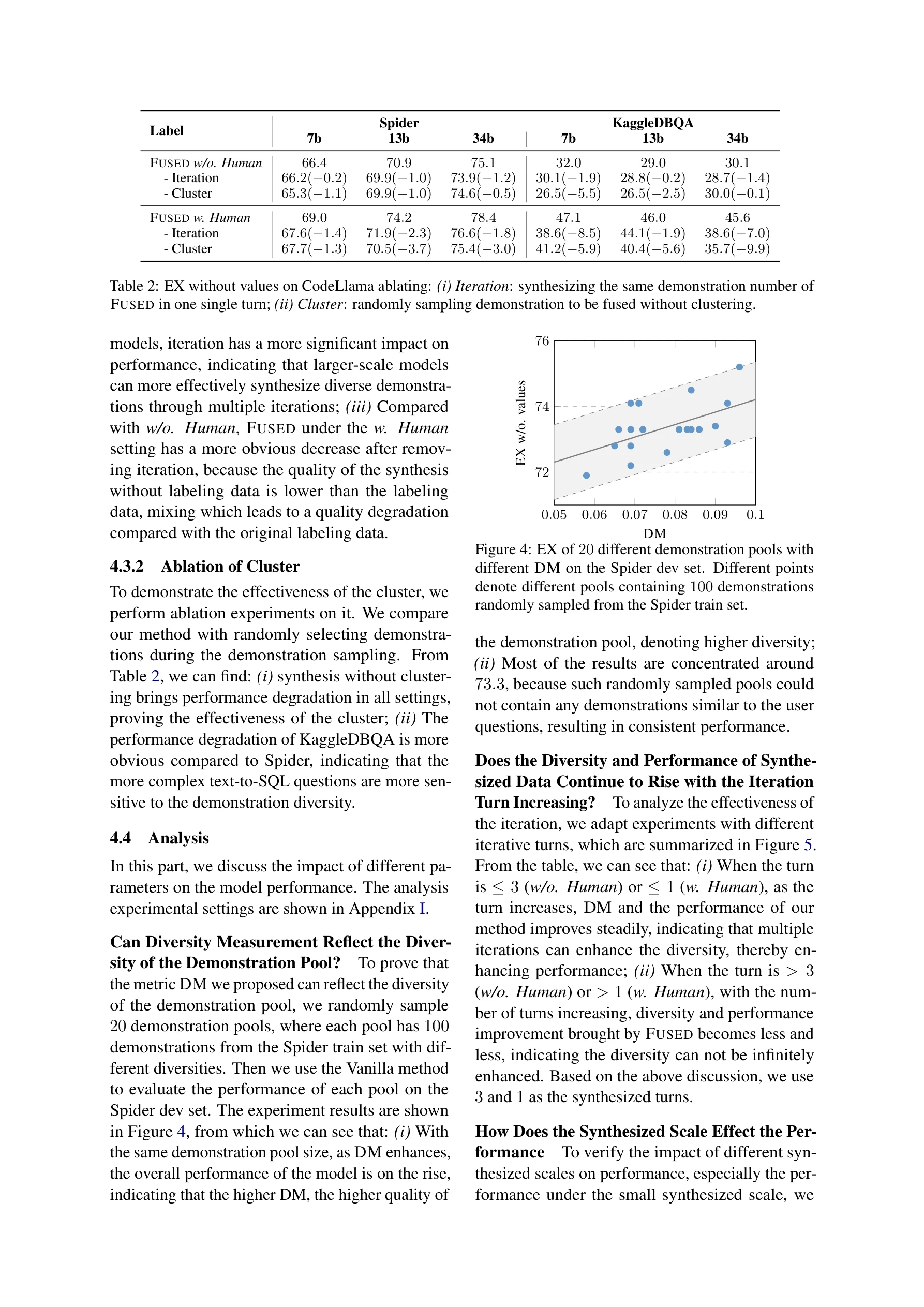
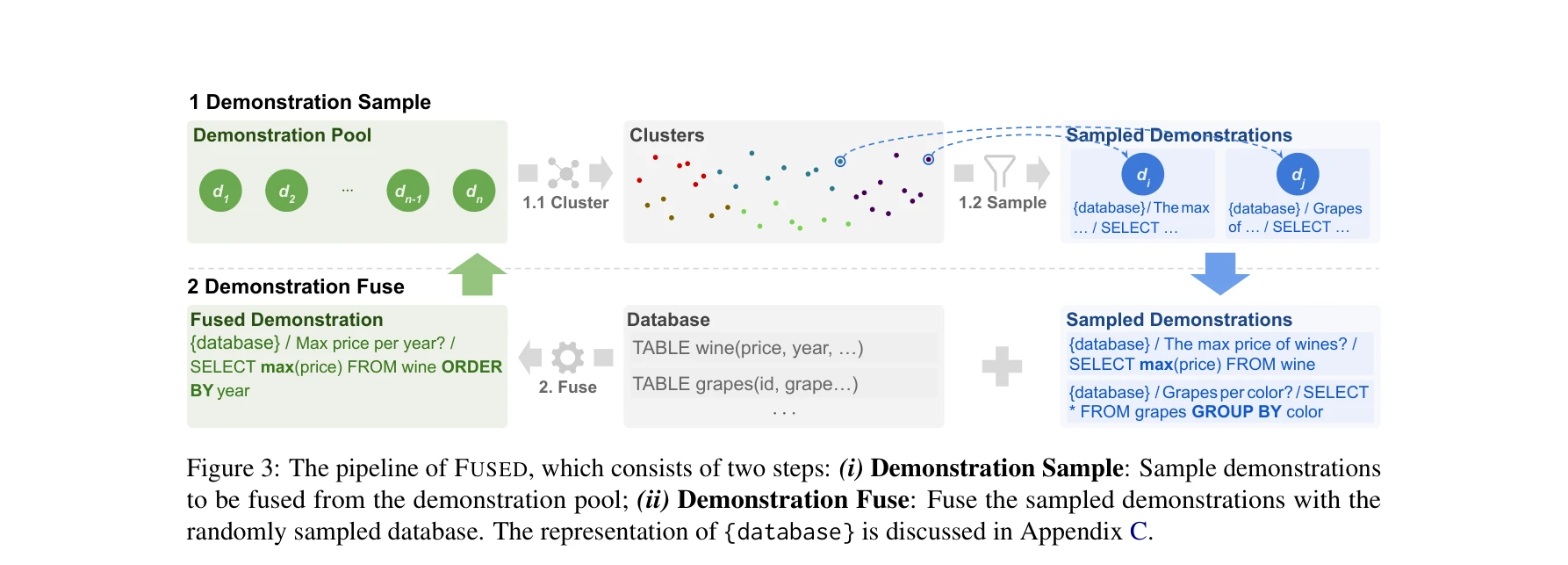
Essence
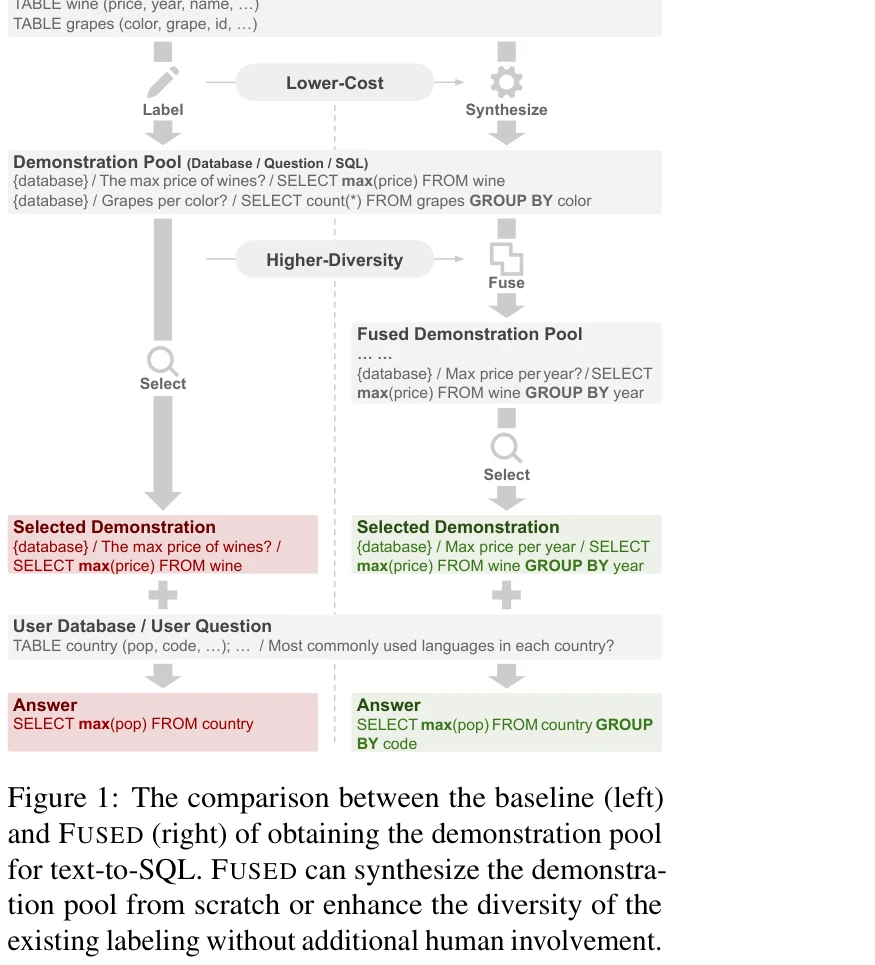
기준선(좌)과 FUSED(우)의 시연(demonstration) 풀 구성 비교. FUSED는 기존 라벨링 없이도 또는 인간 개입 없이 시연 풀을 합성하고 다양성을 향상시킬 수 있음
본 논문은 대규모 언어모델(LLM)의 문맥 내 학습(in-context learning)을 활용한 Text-to-SQL 작업에서 시연(demonstration) 풀의 다양성을 측정하고 향상시키는 방법을 제안한다. 기존의 인간 라벨링 기반 시연 선택 방식의 낮은 다양성과 높은 비용 문제를 해결하기 위해 FUSED(FUSing itEratively for Demonstrations) 방법을 도입한다.