Essence
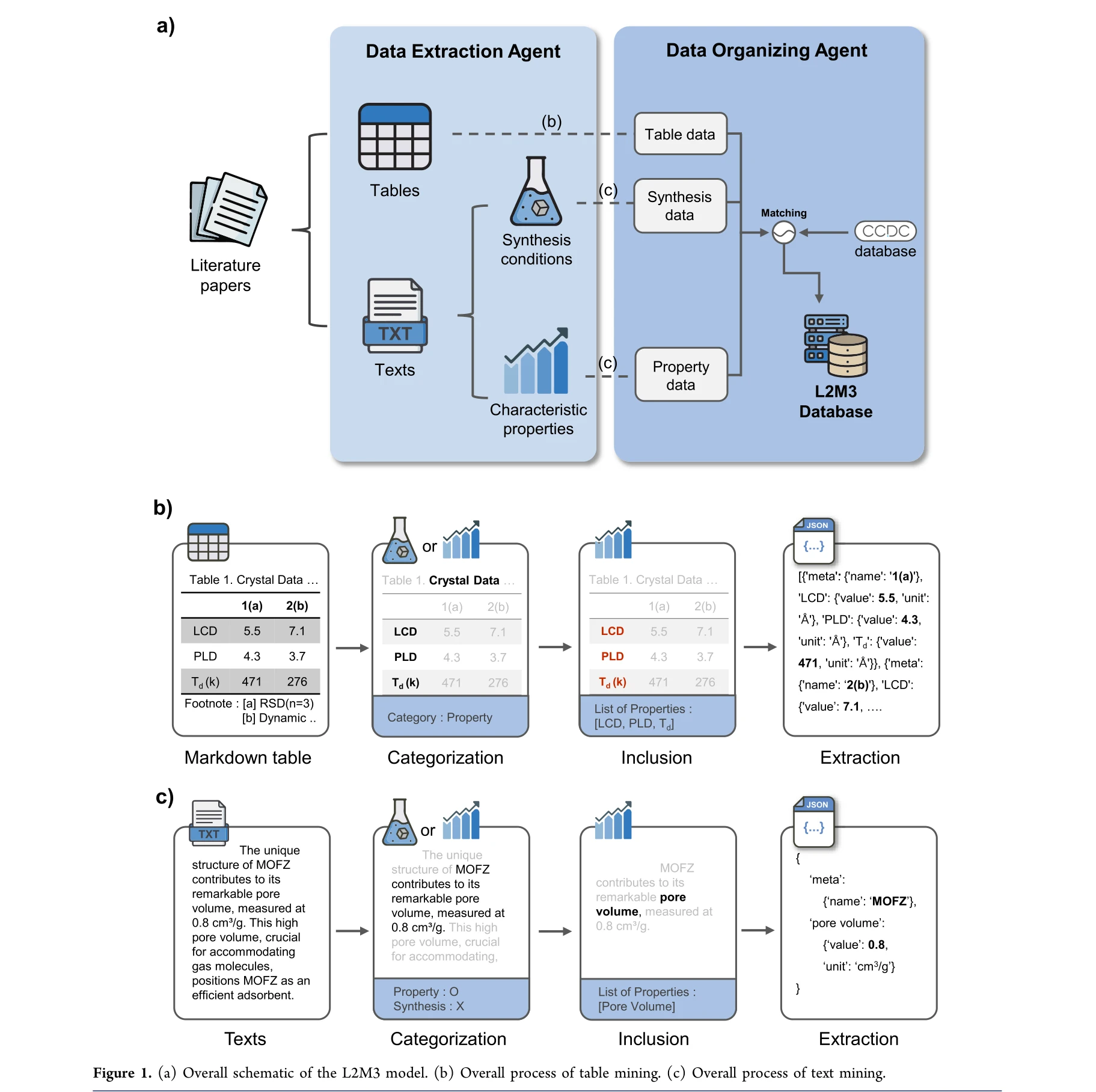
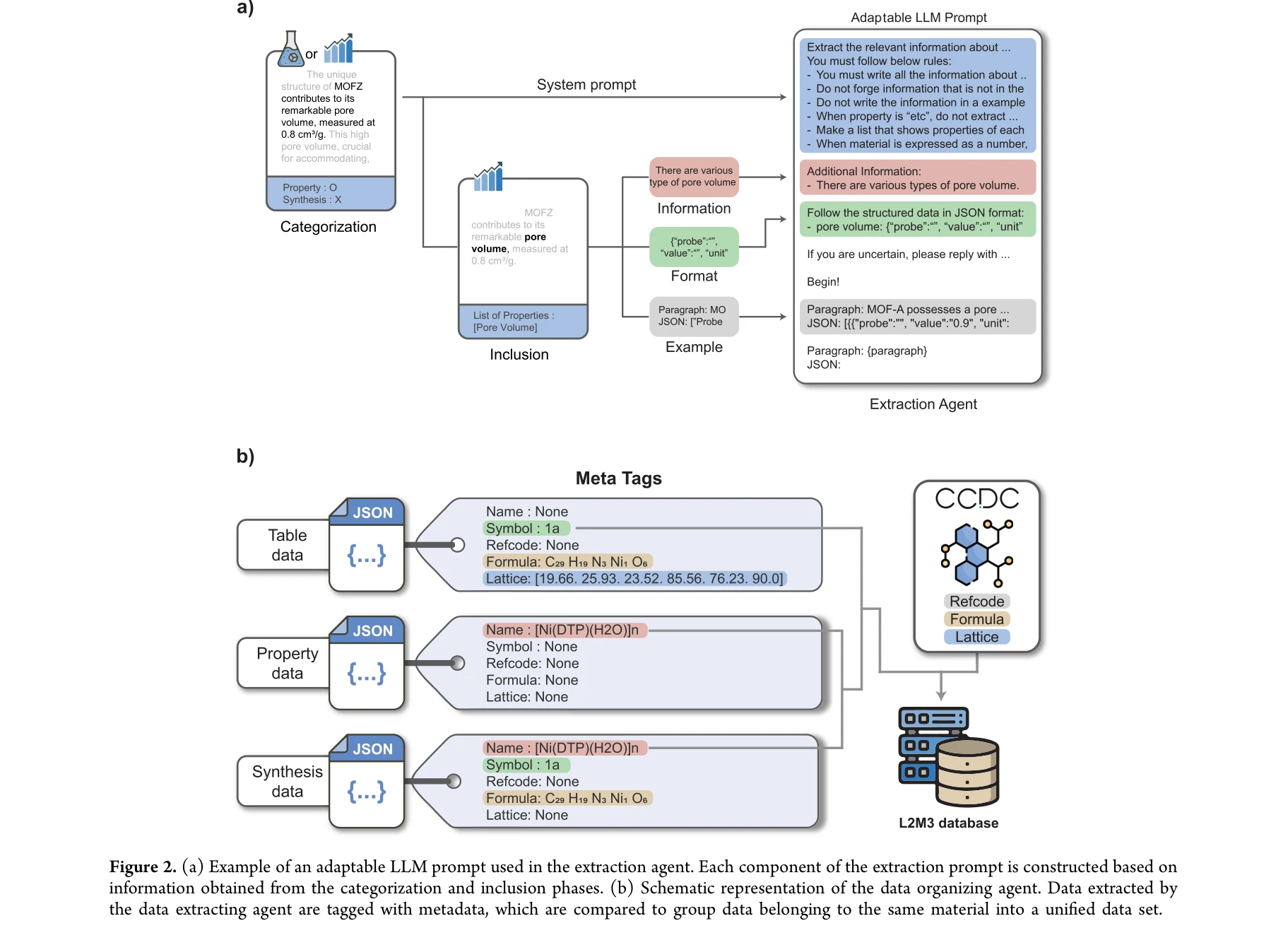
L2M3 모델의 전체 구조: (a) 테이블과 텍스트에서 정보를 추출하는 통합 프레임워크, (b) 테이블 마이닝 프로세스, (c) 텍스트 마이닝 프로세스
대규모 언어모델(LLM)을 활용하여 과학 문헌에서 40,000개 이상의 금속-유기 골격(MOF) 관련 논문을 분석하고, 32개의 핵심 특성과 21개 합성 조건 카테고리를 자동으로 추출한 포괄적인 데이터셋을 구축했다. 이 데이터셋을 통해 합성 조건과 실험 데이터 간의 차이를 규명하고 합성 조건 추천 시스템을 개발했다.
Evaluation
Novelty: 4.5/5 Technical Soundness: 4.2/5 Significance: 4.8/5 Clarity: 4.3/5 Overall: 4.5/5
총평: 본 논문은 LLM 기반 자동화된 데이터 마이닝의 뛰어난 실례로, 40,000개 논문에서 포괄적 MOF 데이터셋을 체계적으로 구축하고 시뮬레이션-실험 간극을 규명했으며 실용적 추천 시스템을 제시함으로써 데이터 기반 물질 과학의 새로운 표준을 제시한다. 다만 LLM 고유의 할루시네이션 위험과 검증 표본의 제한으로 인해 완전한 정확성 보증에는 미치지 못한다.