Essence
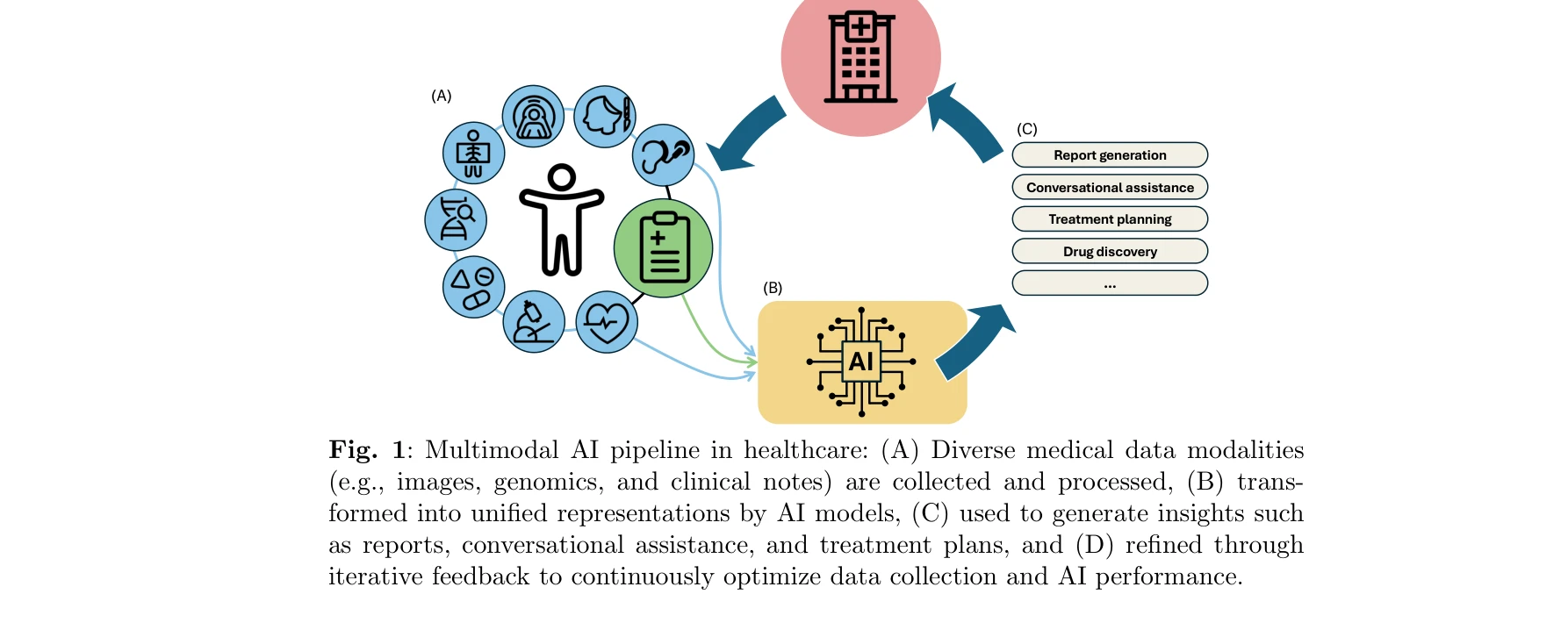
의료 분야의 멀티모달 AI 파이프라인: (A) 다양한 의료 데이터 양식 수집 및 처리, (B) AI 모델에 의한 통합 표현 변환, (C) 리포트 생성, 대화 지원, 치료 계획 등의 인사이트 생성, (D) 피드백을 통한 반복적 최적화
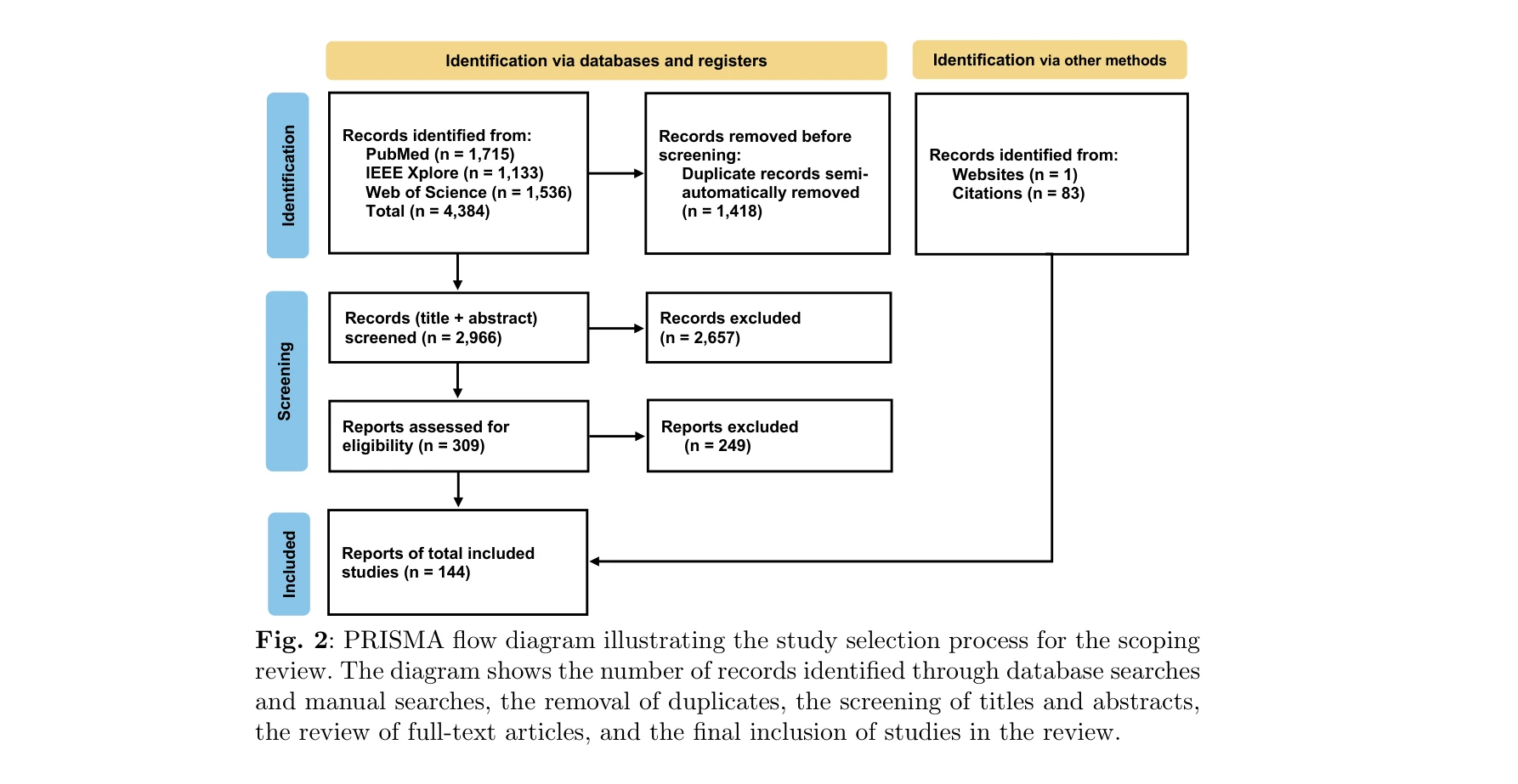
본 논문은 의료 분야에서 생성형 AI의 진화를 체계적으로 검토한 스코핑 리뷰로, 텍스트 기반 대규모 언어모델(LLM)에서 의료 영상, 임상 데이터를 통합하는 멀티모달 AI 시스템으로의 전환을 추적하며, PRISMA-ScR 가이드라인을 따라 2020-2024년 발표된 144개 논문을 분석했다.