Essence
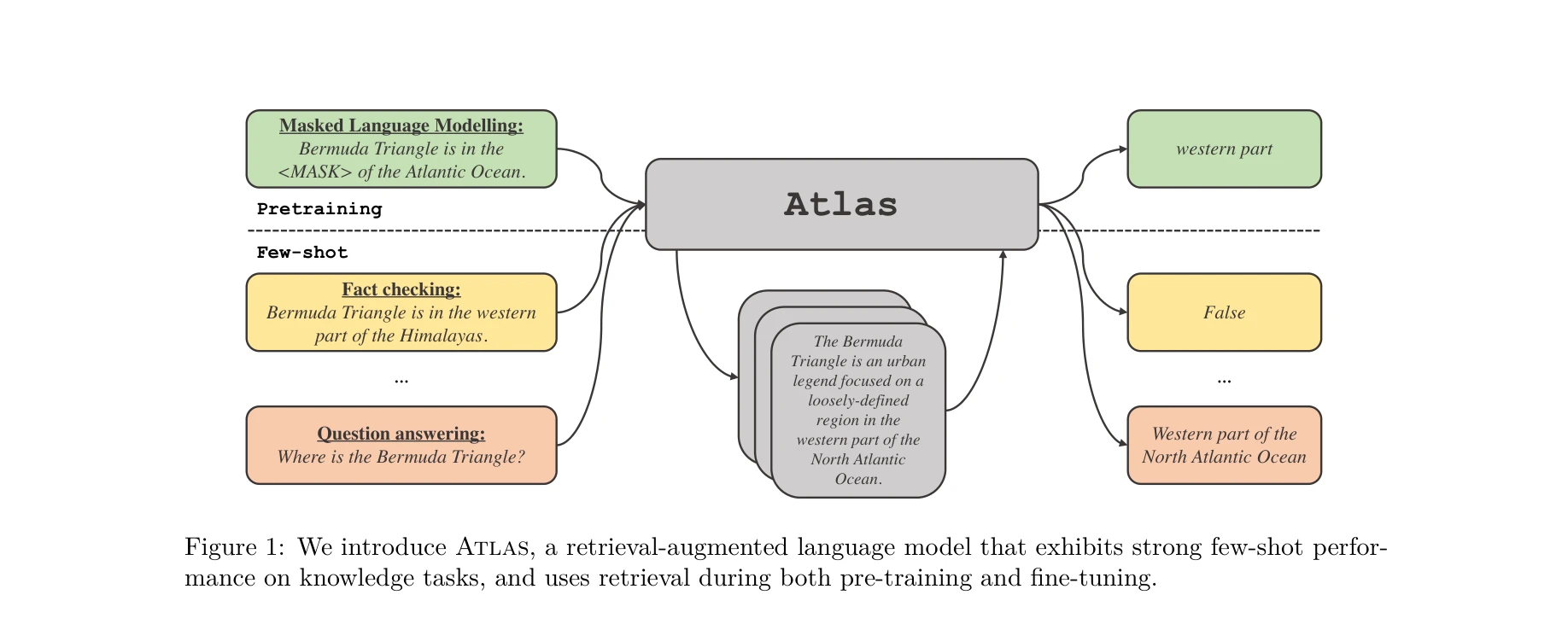
Figure 1: Atlas는 사전학습과 미세조정 단계 모두에서 검색을 활용하는 검색 증강 언어 모델로, 지식 기반 작업에서 강력한 few-shot 성능을 보임
본 논문은 매개변수 메모리에 의존하지 않고 외부 지식 소스를 활용하는 검색 증강 언어 모델(Atlas)을 제시하여, 550억 개 매개변수 모델보다 50배 적은 매개변수(110억)로 우수한 few-shot 학습 성능을 달성한다.
저자: Gautier Izacard, Patrick Lewis, M. Lomeli, Lucas Hosseini, F. Petroni | 날짜: 2022 | DOI: N/A
Figure 1: Atlas는 사전학습과 미세조정 단계 모두에서 검색을 활용하는 검색 증강 언어 모델로, 지식 기반 작업에서 강력한 few-shot 성능을 보임
본 논문은 매개변수 메모리에 의존하지 않고 외부 지식 소스를 활용하는 검색 증강 언어 모델(Atlas)을 제시하여, 550억 개 매개변수 모델보다 50배 적은 매개변수(110억)로 우수한 few-shot 학습 성능을 달성한다.

Figure 2: KILT 벤치마크의 다양한 작업(사실 검증, 질의응답, 엔티티 링킹)에 대한 쿼리-출력 쌍의 예시
총평: 본 논문은 검색 증강 언어 모델의 few-shot 학습 능력을 체계적으로 탐구하여, 매개변수 효율성과 성능 간의 새로운 균형점을 제시한 고품질 연구다. 특히 실무 적용 가능성과 지식 업데이트 용이성 측면에서 학계와 산업계에 모두 기여할 수 있는 중요한 작업이다.