Essence

그림 1: 전문가가 수동으로 상관관계를 평가하는 방식과 LLM이 도움을 주는 방식
LLM의 내부 지식을 활용하여 변수 쌍의 예상 상관계수에 대한 사전분포(prior distribution)를 자동으로 구성하고, 이를 통해 관찰된 상관관계가 얼마나 놀라운지(surprising)를 정량화함으로써 수천 개의 발견된 상관관계 중 주목할 가치가 있는 것을 자동으로 필터링하는 방법을 제안한다.
저자: Yue Gong, R. Fernandez | 날짜: 2025 | DOI: 10.48550/arXiv.2506.03444
그림 1: 전문가가 수동으로 상관관계를 평가하는 방식과 LLM이 도움을 주는 방식
LLM의 내부 지식을 활용하여 변수 쌍의 예상 상관계수에 대한 사전분포(prior distribution)를 자동으로 구성하고, 이를 통해 관찰된 상관관계가 얼마나 놀라운지(surprising)를 정량화함으로써 수천 개의 발견된 상관관계 중 주목할 가치가 있는 것을 자동으로 필터링하는 방법을 제안한다.
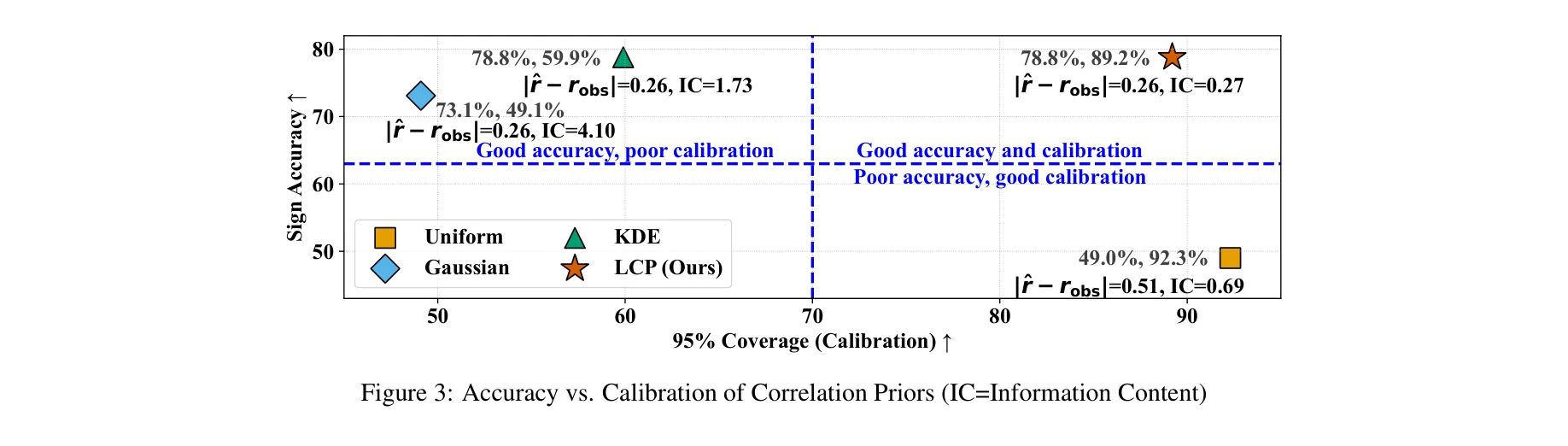
그림 3: 다양한 상관관계 사전분포의 정확도 vs. 보정 성능 비교(IC=정보량)

그림 2: 높은 상관관계 값에 대한 편향 분석
Logit-based Calibrated Prior(LCP) 구성 방법:
핵심 수식:
$$f(r) = \frac{1}{Z}\sum_{j=1}^{N} p_j \cdot \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(r-r_j)^2}{2\sigma^2}\right), \quad r \in [-1, 1]$$
여기서 σ는 커널의 표준편차로, 불확실성을 제어한다.
총평: 본 논문은 가설 평가의 자동화라는 실질적이고 중요한 문제를 설정하고, LLM의 로짓으로부터 보정된 상관관계 사전분포를 구성하는 창의적이고 실행 가능한 방법을 제시한다. 2,096개 변수 쌍에 대한 포괄적인 벤치마크와 다각적 평가를 통해 방법의 유효성을 입증했으나, 현재로서는 상관관계에만 적용되고 다른 통계적 관계나 인과관계로의 확장이 부족하다는 점이 영향을 미친다.