Essence
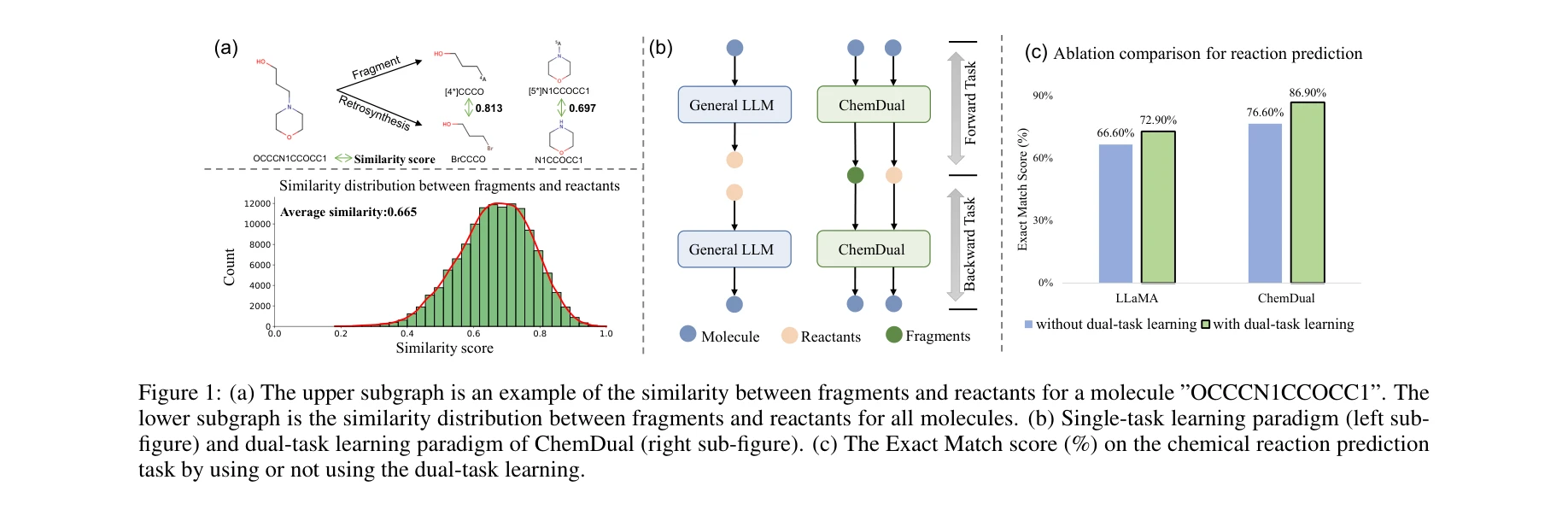
BRICS 기반 단편(fragment)과 반응물(reactant) 간의 유사성 분포(평균 66.5%) 및 이중 과제 학습을 통한 성능 향상(6.3% 개선)
본 논문은 대규모 언어 모델(LLM)을 화학 반응 및 역합성 예측에 적용할 때 직면하는 데이터 부족과 과제 간 상관관계 무시 문제를 해결하기 위해, BRICS 기반 440만 개 분자 데이터셋과 이중 과제 학습 전략을 갖춘 ChemDual 프레임워크를 제안한다.
저자: Xuan Lin, Qingrui Liu, Hongxin Xiang, Daojian Zeng, Xiangxiang Zeng | 날짜: 2025 | DOI: arXiv:2505.02639
BRICS 기반 단편(fragment)과 반응물(reactant) 간의 유사성 분포(평균 66.5%) 및 이중 과제 학습을 통한 성능 향상(6.3% 개선)
본 논문은 대규모 언어 모델(LLM)을 화학 반응 및 역합성 예측에 적용할 때 직면하는 데이터 부족과 과제 간 상관관계 무시 문제를 해결하기 위해, BRICS 기반 440만 개 분자 데이터셋과 이중 과제 학습 전략을 갖춘 ChemDual 프레임워크를 제안한다.
ChemDual의 전체 구조: 데이터셋 구축, 다중 규모 토크나이저, 이중 과제 학습 모듈
지시문 세트 예시: 역합성(전방 과제)과 반응 예측(후방 과제)
Dataset Construction (3.1절)
n = L (LMulti-scale Tokenizer (3.2절)
Dual-task Learning (3.3절)
총평: ChemDual은 BRICS 기반 저비용 대규모 데이터셋과 화학적 직관에 기반한 이중 과제 학습으로 화학 반응/역합성 예측에서 의미 있는 성능 향상을 달성했으며, 약물 설계 응용 가능성을 실증했다. 다만 단편화 방법의 한계, 해석 가능성 부족, 평가 범위 확대의 필요성이 향후 개선 방향이다.