Essence
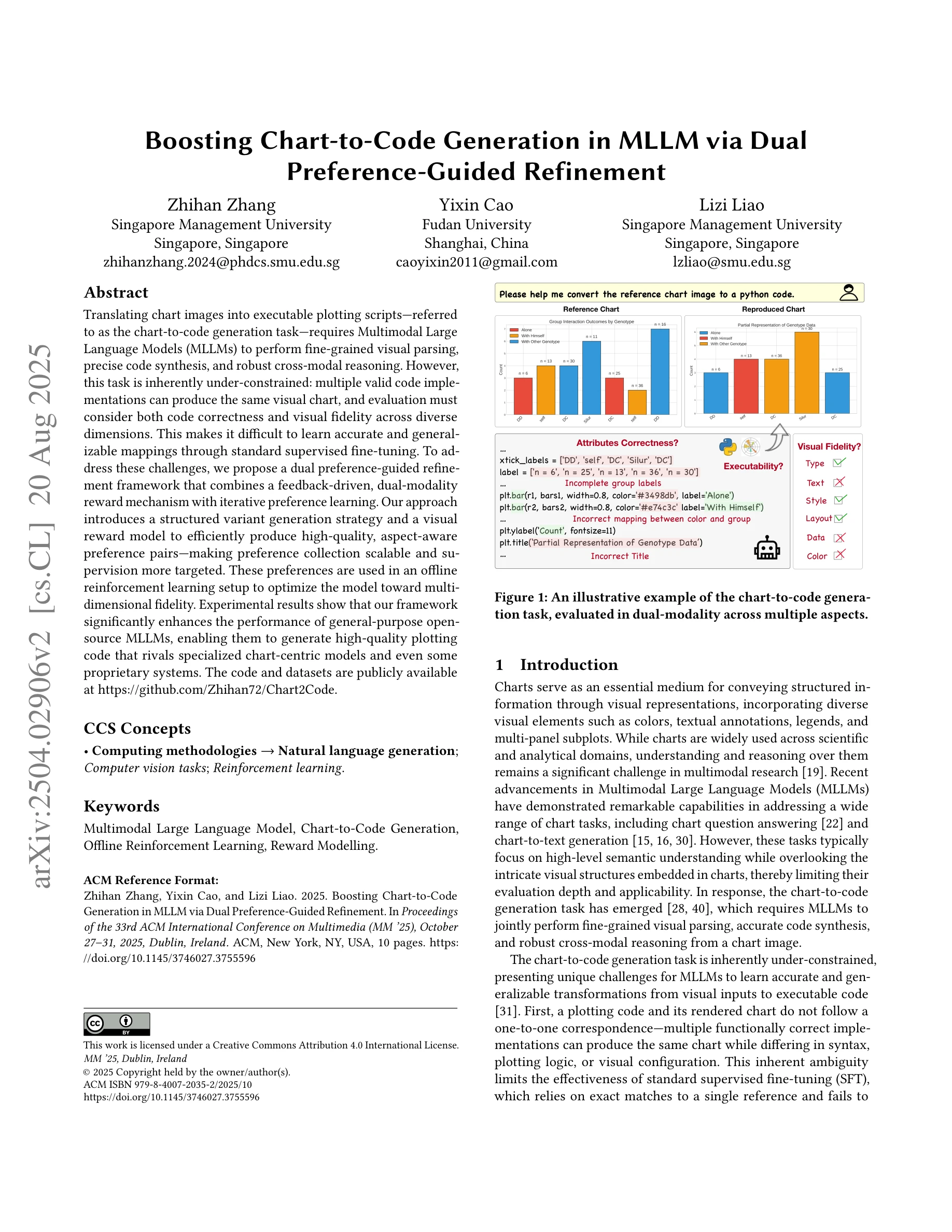
차트-to-코드 생성 작업의 예시로, 실행 가능성(Executability), 시각적 충실도(Visual Fidelity), 속성 정확도(Attributes Correctness) 등 다중 차원으로 평가됨
차트 이미지를 실행 가능한 플로팅 코드로 변환하는 차트-to-코드 생성 작업에서, 다중모달 대규모 언어 모델(MLLM)의 성능을 향상시키기 위해 이중 모드(code + image) 보상 메커니즘과 반복적 선호도 학습을 결합한 프레임워크를 제시한다.
How

각 반복 단계에서 생성되는 보상 신호의 흐름
1. 이중 보상 메커니즘 (Dual Rewarding Mechanism)
- 코드 측 평가: 휴리스틱 F1 기반 점수 매기기로 생성 코드의 구조적 완정성과 의미론적 정확성 평가
- 차트 타입(Type), 데이터(Data), 색상(Color), 텍스트(Text), 레이아웃(Layout), 스타일(Style) 등 6개 종횡에 대해 개별 F1 점수 계산
- 이미지 측 평가: 시각 보상 모델(visual reward model)을 통해 렌더링된 차트의 시각적 충실도 평가
- 종횡별 피드백 데이터셋으로 훈련된 시각 보상 모델이 레이아웃, 스타일, 지각적 속성 보존 정도 측정
2. 구조화된 변형 생성 전략 (Structured Variant Generation)
- 금표준 코드로부터 제어된 편차를 가진 합성 코드 샘플 생성
- 종횡별 규칙 기반 변형: Shuffling(색상 재정렬), Removing(텍스트 제거), Changing(스타일 변경) 등
- 다양한 재현 수준에 걸친 선호도 쌍 생성
3. 반복적 선호도 학습 (Iterative Preference Learning)
- Direct Preference Optimization (DPO) 목표함수 활용
- 모델 생성 코드 vs 합성 변형 코드 간 선호도 쌍 구성
- 각 반복 종료 후 새로운 참조 차트 배치에 대해 모델 평가하여 다음 반복 진행
- 이중 피드백 기반 최적화로 지속적 정제
4. 종횡별 피드백 데이터셋 구성
- 각 생성 결과에 대해 종횡별 설명과 점수 제공
- 시각 보상 모델 훈련의 감독 신호로 사용
