Essence
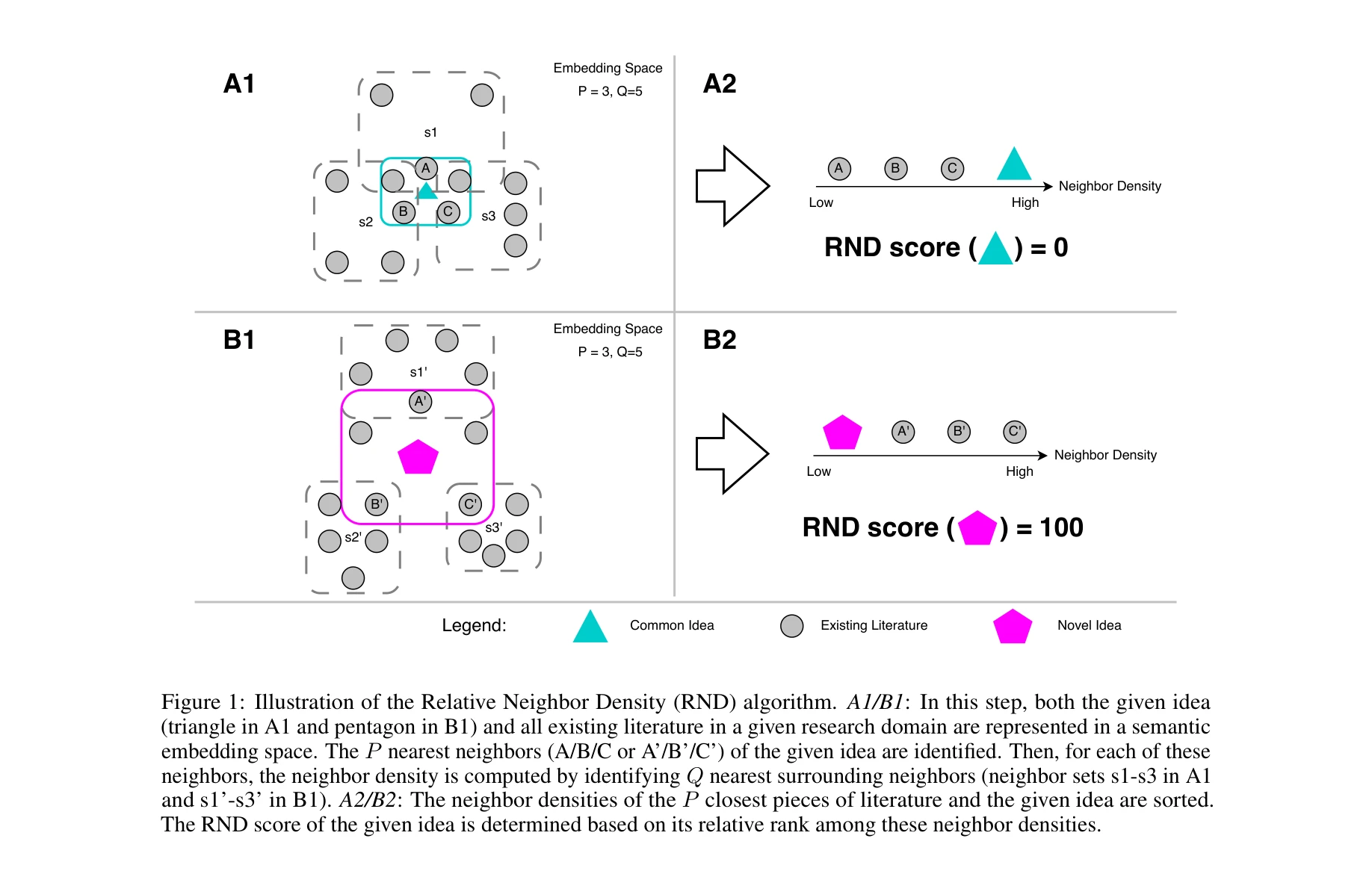
RND 알고리즘의 개념 도시: 주어진 아이디어(삼각형/오각형)와 기존 문헌을 의미론적 임베딩 공간에 표현한 후, P개의 최근접 이웃을 찾고 각 이웃의 주변 밀도(Q개의 이웃 기준)를 계산하여 상대적 순위로 혁신성 점수를 결정
대규모 언어모델(LLM)이 생성한 연구 아이디어의 혁신성을 자동 평가하기 위해 상대 이웃 밀도(Relative Neighbor Density, RND) 알고리즘을 제안한다. 이 방법은 절대적 국소 밀도가 아닌 의미론적 이웃들의 상대적 밀도 분포를 분석하여 도메인 간 일관된 성능을 달성한다.
How
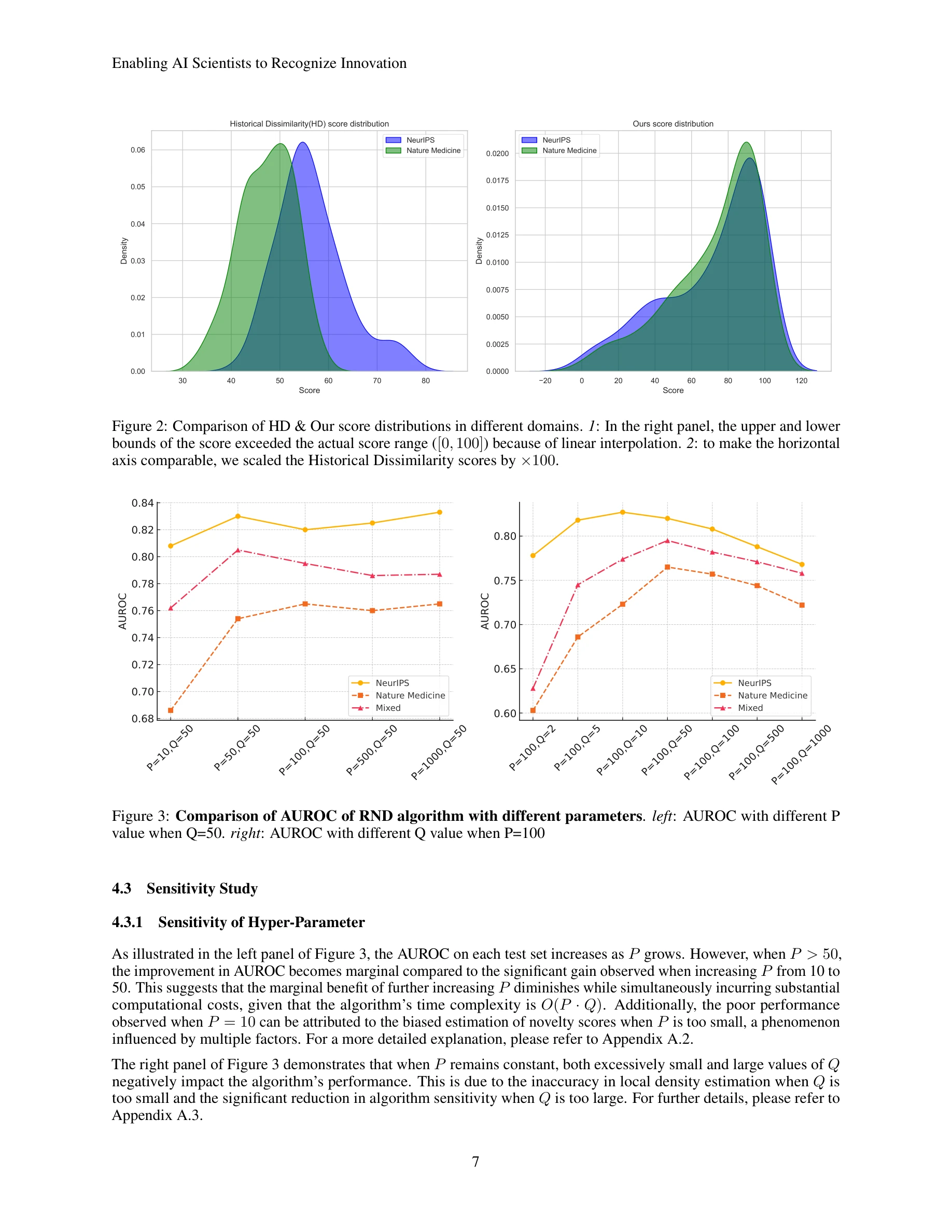
RND 알고리즘의 P(최근접 이웃 수)와 Q(이웃의 이웃 수) 파라미터에 따른 AUROC 변화: P=100, Q=50에서 최적
- 의미론적 임베딩: 각 논문의 제목과 초록을 M3-Embedding으로 1024차원 벡터로 변환
- 이웃 밀도(ND) 계산: 아이디어 임베딩 v와 Q개의 최근접 논문 사이의 코사인 거리 평균의 역수
$$ND = \frac{1}{Q}\sum_{k=1}^{Q}d(v, v_k)$$
- 상대 순위 기반 점수화: 아이디어의 P개 최근접 이웃 중 아이디어보다 밀도가 낮은 이웃의 비율로 최종 점수 결정
$$score_i = \frac{|\{ND \in S_i | ND \leq ND_i\}|}{|S_i|} \times 100$$
- 핵심 통찰: 절대값 대신 상대 순위를 사용하므로 도메인 간 밀도 편차에 불변(domain-invariant)
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 5/5 Overall: 4/5
총평: 혁신성 평가의 도메인 간 일반화를 상대 밀도 개념으로 우아하게 해결하고, 전문가 라벨링 불필요한 검증 방법론으로 스케일 가능성을 입증했다. LLM 과학자 시대의 실질적 요구에 부응하는 견고한 기술 기여이나, 테스트셋 라벨링의 철학적 가정(시간 경과 = 비혁신성)과 다양한 임베딩 모델의 영향에 대한 더 깊은 논의가 필요하다.