Achievement
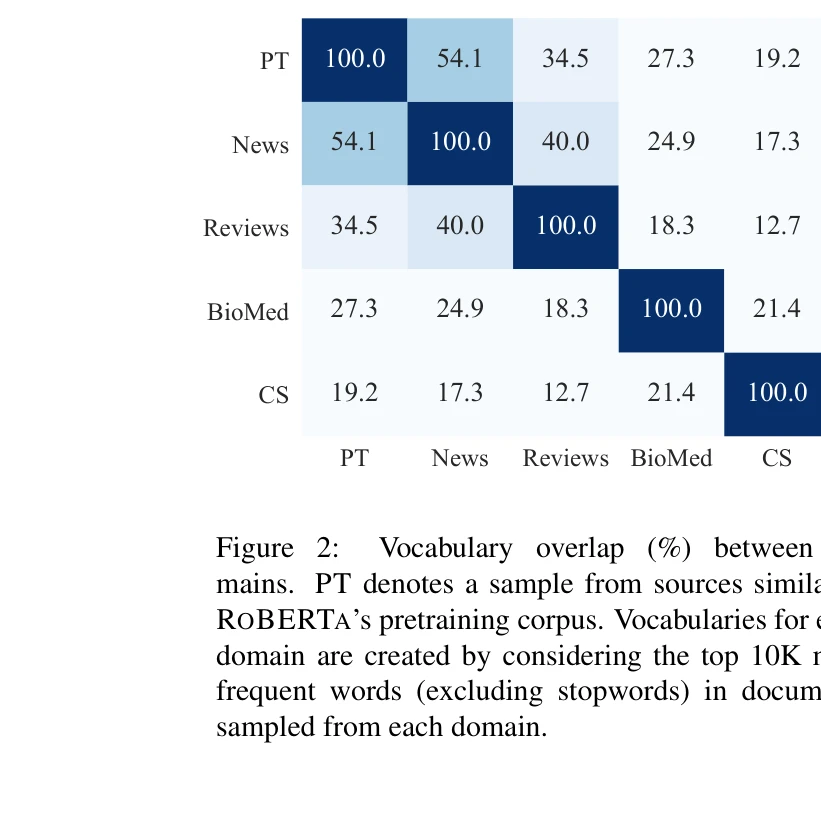
어휘 중복도를 통한 도메인 유사성 분석: CS와 생의학(BioMed) 도메인이 PT 도메인과 가장 멀리 떨어져 있음
- 도메인 적응 사전학습(DAPT)의 일관된 효과: 생의학, CS, 리뷰 도메인에서 RoBERTa 대비 지속적 성능 향상 달성(예: ACL-ARC 63.0% → 75.4%, CHEMPROT 81.9% → 84.2%). 고자원/저자원 설정 모두에서 개선 확인
- 도메인 적응과 작업 적응의 상승 효과: DAPT 후 TAPT를 추가로 적용하면 더 큰 성능 향상 달성, 즉 다단계 적응 사전학습(multi-phase adaptive pretraining)이 효과적임을 입증
- 도메인 관련성의 중요성: 무관한 도메인으로 적응한 경우(¬DAPT) RoBERTa보다 성능이 악화되어, 단순 데이터 노출 증가가 아닌 도메인 관련성이 핵심 요인임을 증명
- 자동 데이터 선택 전략: 인간 큐레이션 데이터 부재 시 간단한 데이터 선택 전략으로 작업 적응 사전학습 성능을 향상시킬 수 있는 실용적 대안 제시