Essence
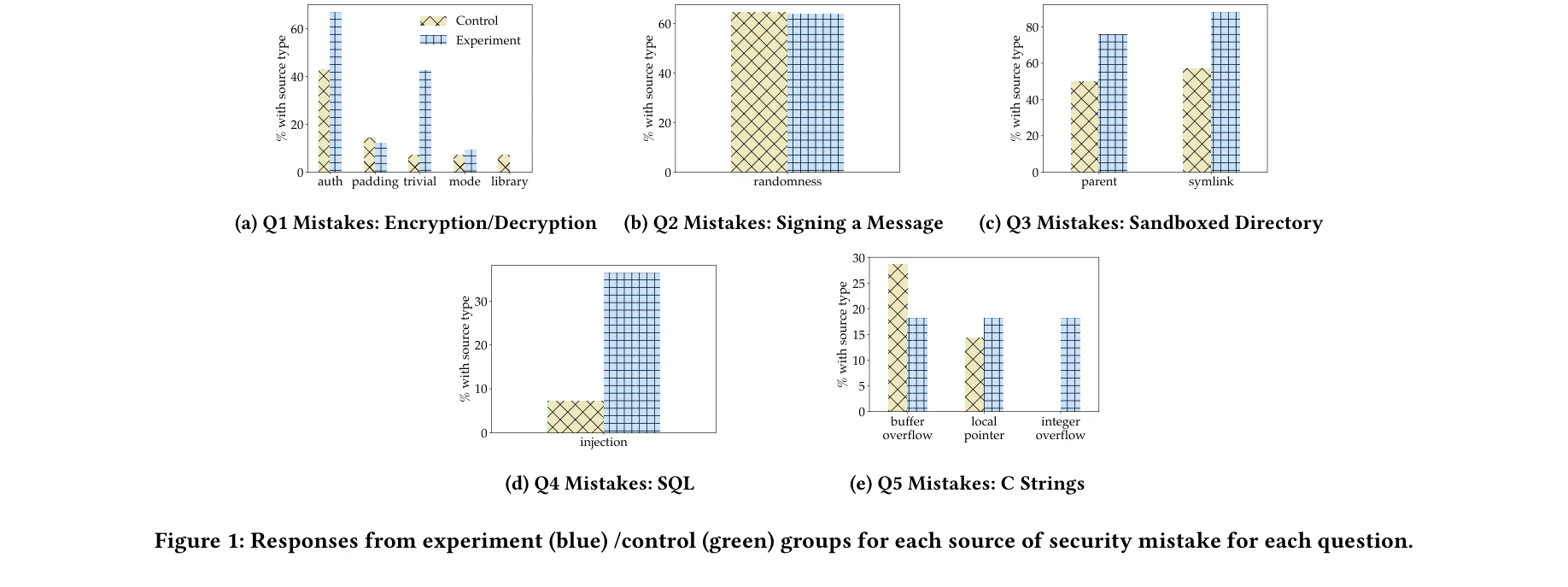
Figure 1: 각 질문별 보안 실수 원인별 실험군(파란색)/대조군(녹색) 응답 분포
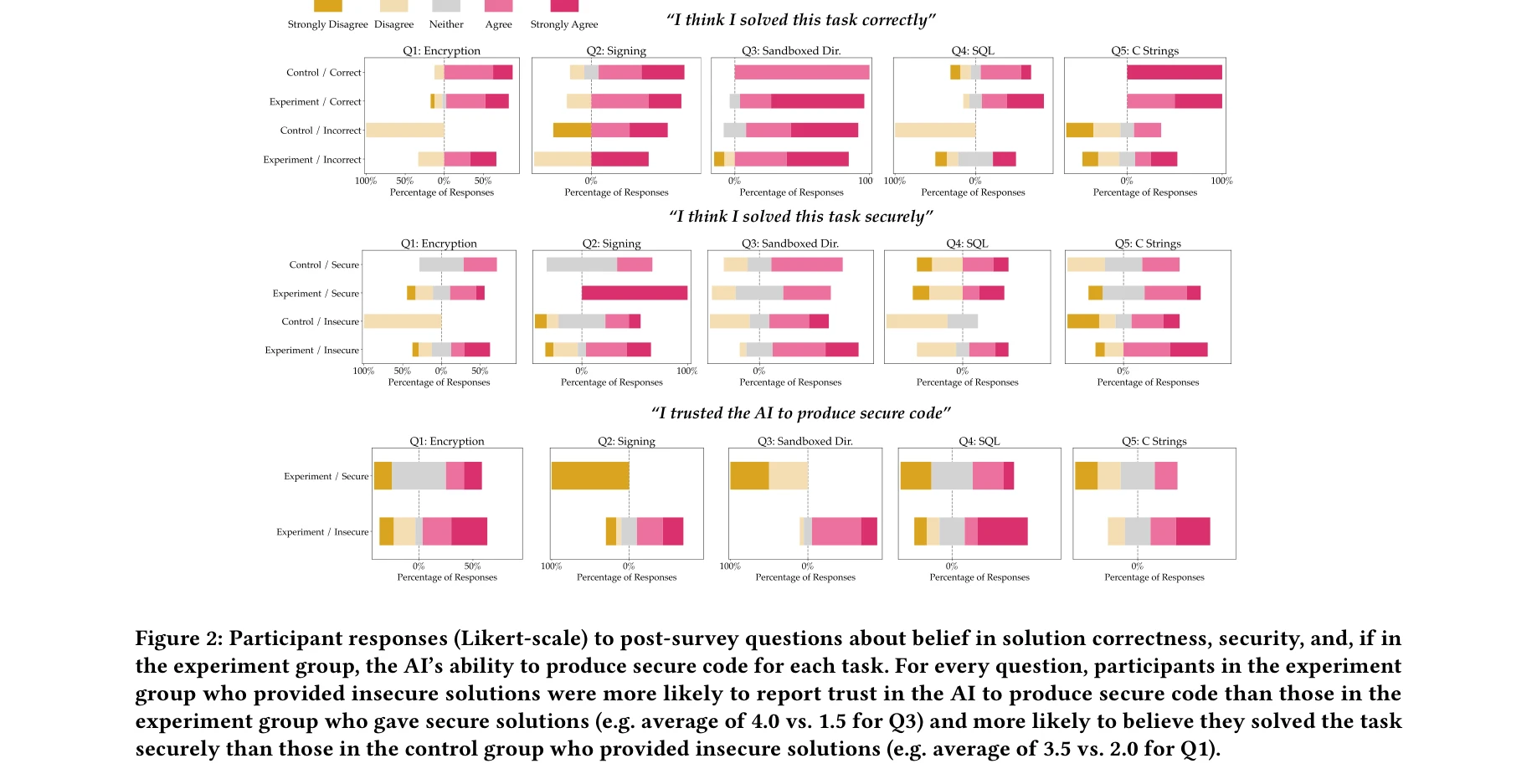
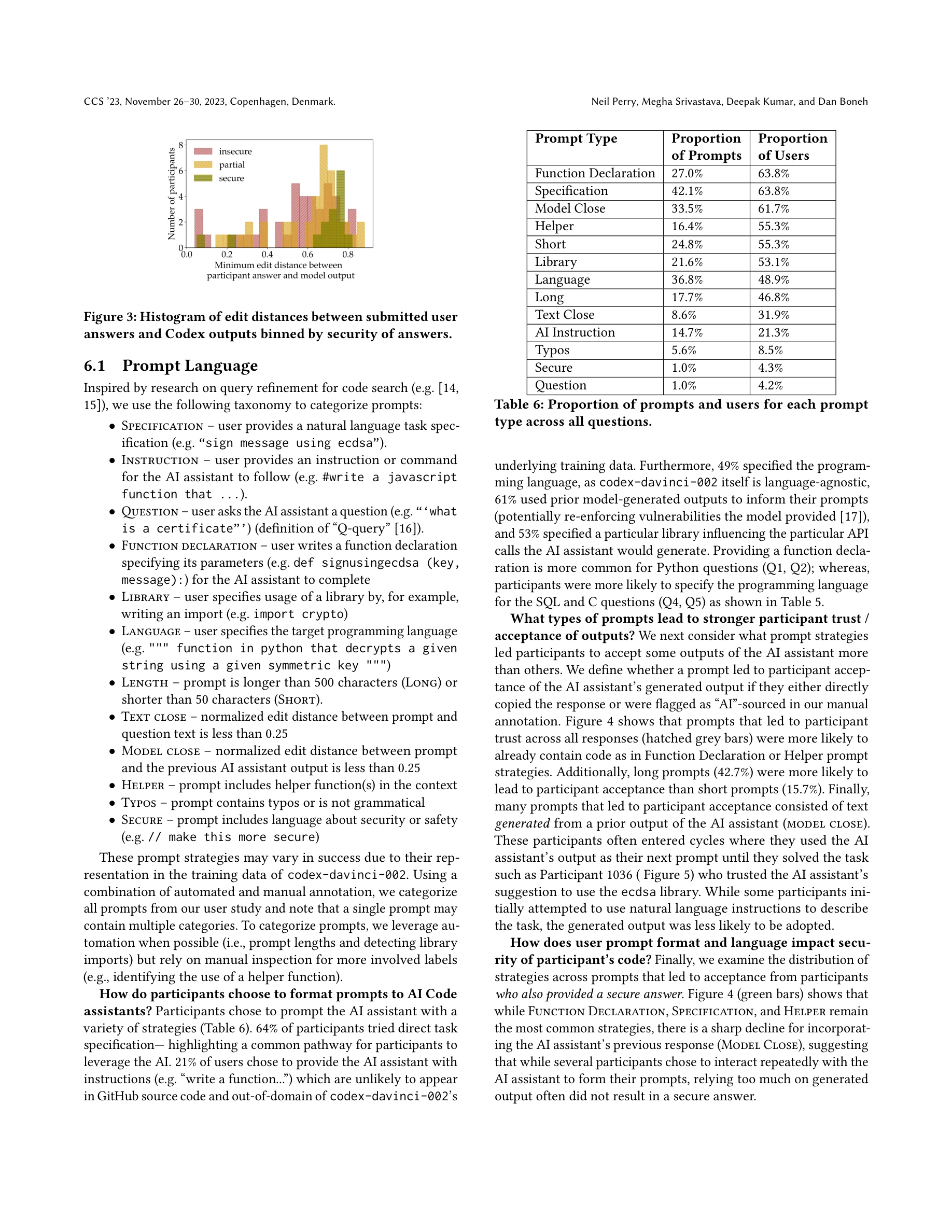
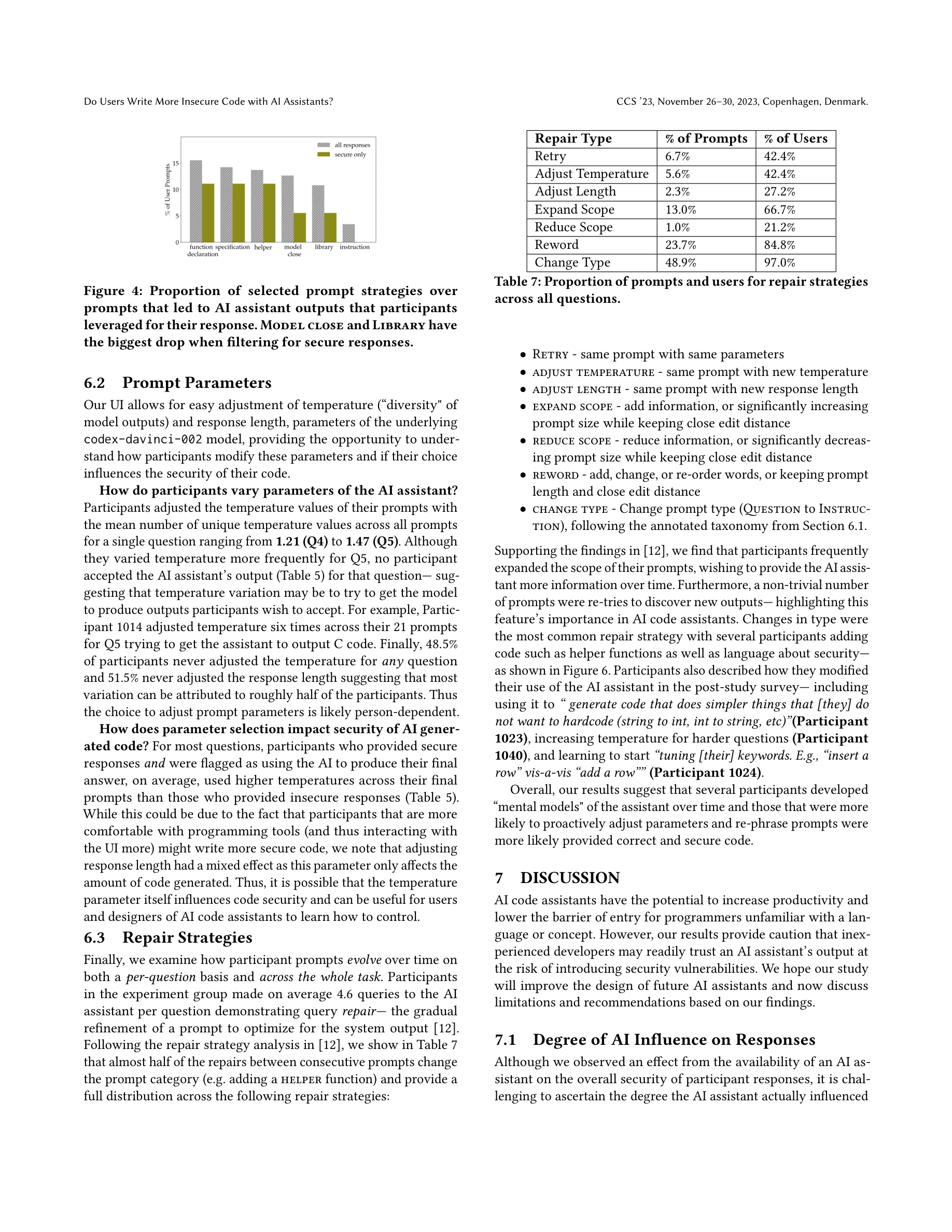
본 논문은 AI 코드 어시스턴트 사용자가 보안 관련 프로그래밍 작업을 수행할 때 더 안전하지 못한 코드를 작성하는지 대규모 사용자 실험을 통해 조사했다. 연구 결과 AI 어시스턴트(OpenAI's Codex-davinci-002)에 접근한 참가자들이 접근하지 못한 참가자들보다 유의미하게 보안 취약점이 많은 코드를 작성했으며, 역설적으로 자신의 코드가 안전하다고 더 높은 확률로 믿었다.