저자: Bodhisattwa Prasad Majumder, Harshit Surana, D. P. Agarwal, Bhavana Dalvi Mishra, Abhijeetsingh Meena, Aryan Prakhar, Tirth Vora, Tushar Khot, Ashish Sabharwal, Peter E. Clark | 날짜: 2024 | DOI: N/A
Essence
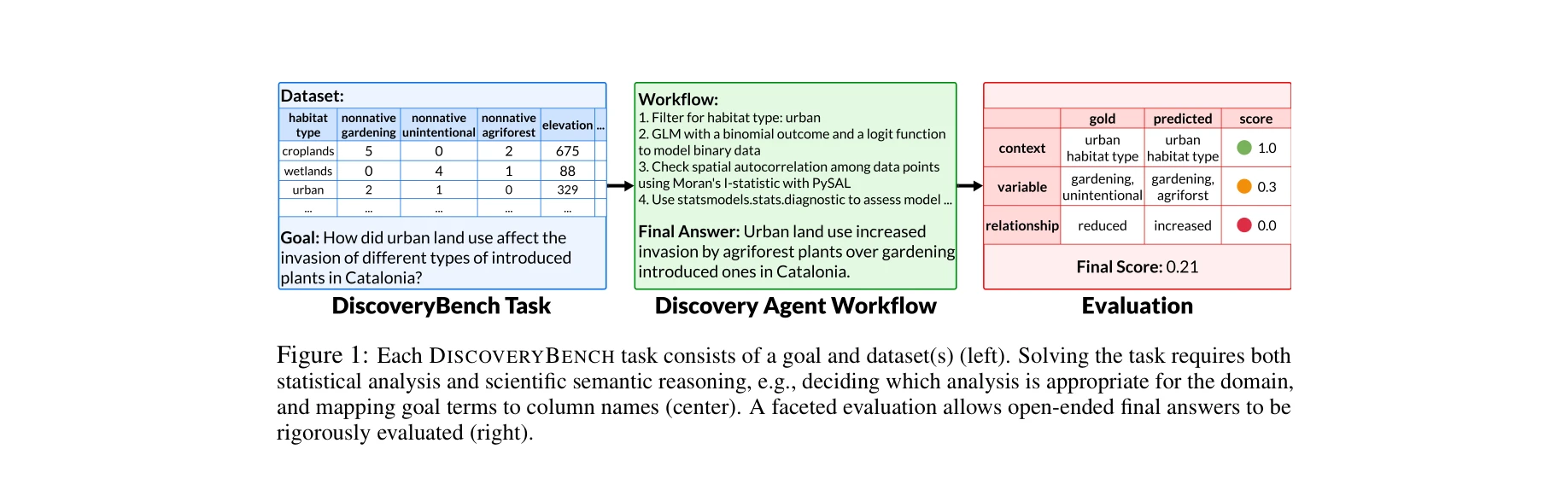
각 DiscoveryBench 과제는 목표와 데이터셋으로 구성되며, 통계 분석과 과학적 의미 추론이 필요하고, 다면적 평가를 통해 엄밀하게 평가됨
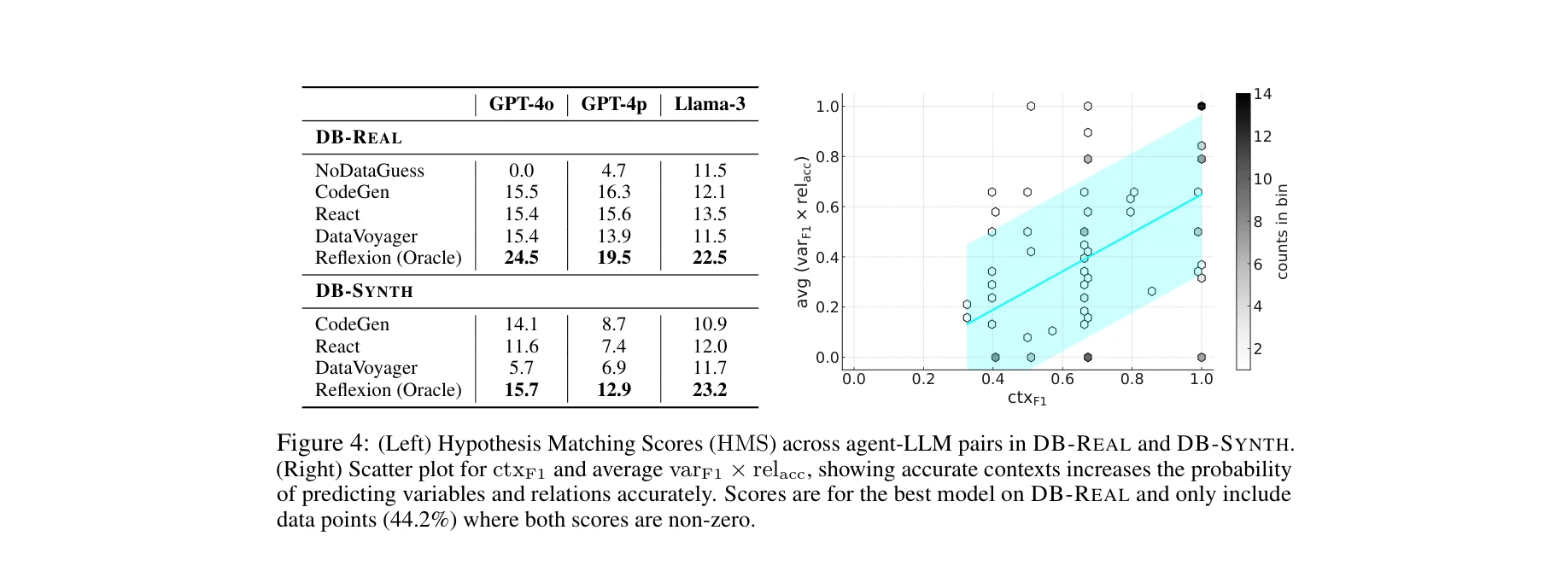
본 논문은 대규모 언어모델(LLM)이 데이터셋만으로 가설을 자동으로 탐색하고 검증할 수 있는지 평가하기 위한 최초의 포괄적 벤치마크 DiscoveryBench를 제시한다. 264개의 실제 과제와 903개의 합성 과제로 구성되어 있으며, 현재 최고 성능 LLM도 25%의 정확도만 달성하여 자동화된 데이터 기반 발견의 난제를 드러낸다.
Evaluation
총평: DiscoveryBench는 LLM 기반 자동화된 과학적 발견의 능력을 체계적으로 평가하는 중요한 첫 번째 벤치마크로서, 새로운 형식화 프레임워크와 다면적 평가 메커니즘을 제시한다. 264개의 실제 과제와 903개의 합성 과제로 구성된 포괄적인 자원을 제공하며, 현재 LLM의 25% 저조한 성능은 이 분야의 미해결 과제를 명확히 드러낸다. 다만 평가 일관성 검증이 보완되고, 실패 모드에 대한 더 깊은 분석이 이루어진다면 이 벤치마크는 향후 과학적 발견 자동화 연구의 중요한 추진력이 될 것으로 기대된다.