Essence
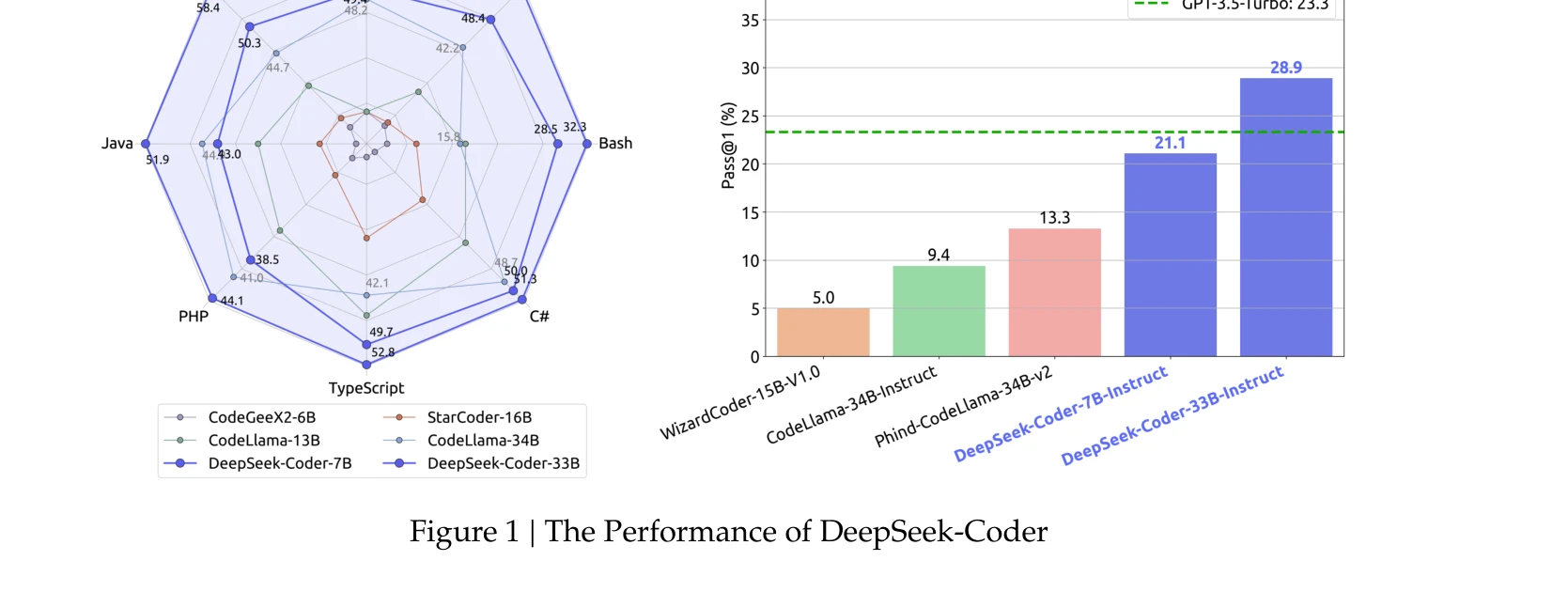
DeepSeek-Coder의 성능 비교
본 논문은 1.3B에서 33B 규모의 오픈소스 코드 전문 대규모 언어모델(LLM) 시리즈를 제시하며, 폐쇄형 모델인 Codex와 GPT-3.5를 능가하는 성능을 달성했다. 2조 개의 토큰으로 학습된 이 모델들은 저작권 제약 없이 상용 사용 가능한 오픈소스로 제공된다.
저자: Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y.K. Li, Fuli Luo, Yingfei Xiong, Wenfeng Liang | 날짜: 2024 | DOI: -
DeepSeek-Coder의 성능 비교
본 논문은 1.3B에서 33B 규모의 오픈소스 코드 전문 대규모 언어모델(LLM) 시리즈를 제시하며, 폐쇄형 모델인 Codex와 GPT-3.5를 능가하는 성능을 달성했다. 2조 개의 토큰으로 학습된 이 모델들은 저작권 제약 없이 상용 사용 가능한 오픈소스로 제공된다.

데이터셋 생성 절차: 데이터 크롤링 → 규칙 필터링 → 의존성 파싱 → 저장소 수준 중복 제거 → 품질 스크리닝
총평: DeepSeek-Coder는 저장소 수준 의존성 분석이라는 신선한 접근과 철저한 데이터 관리를 통해 오픈소스 코드 모델의 새로운 기준을 수립했으며, GPT-3.5 추월 성과는 코드 AI의 민주화에 중대한 기여를 한다. 다만 의존성 추출의 정확성 검증과 언어 편향 완화가 후속 과제이다.