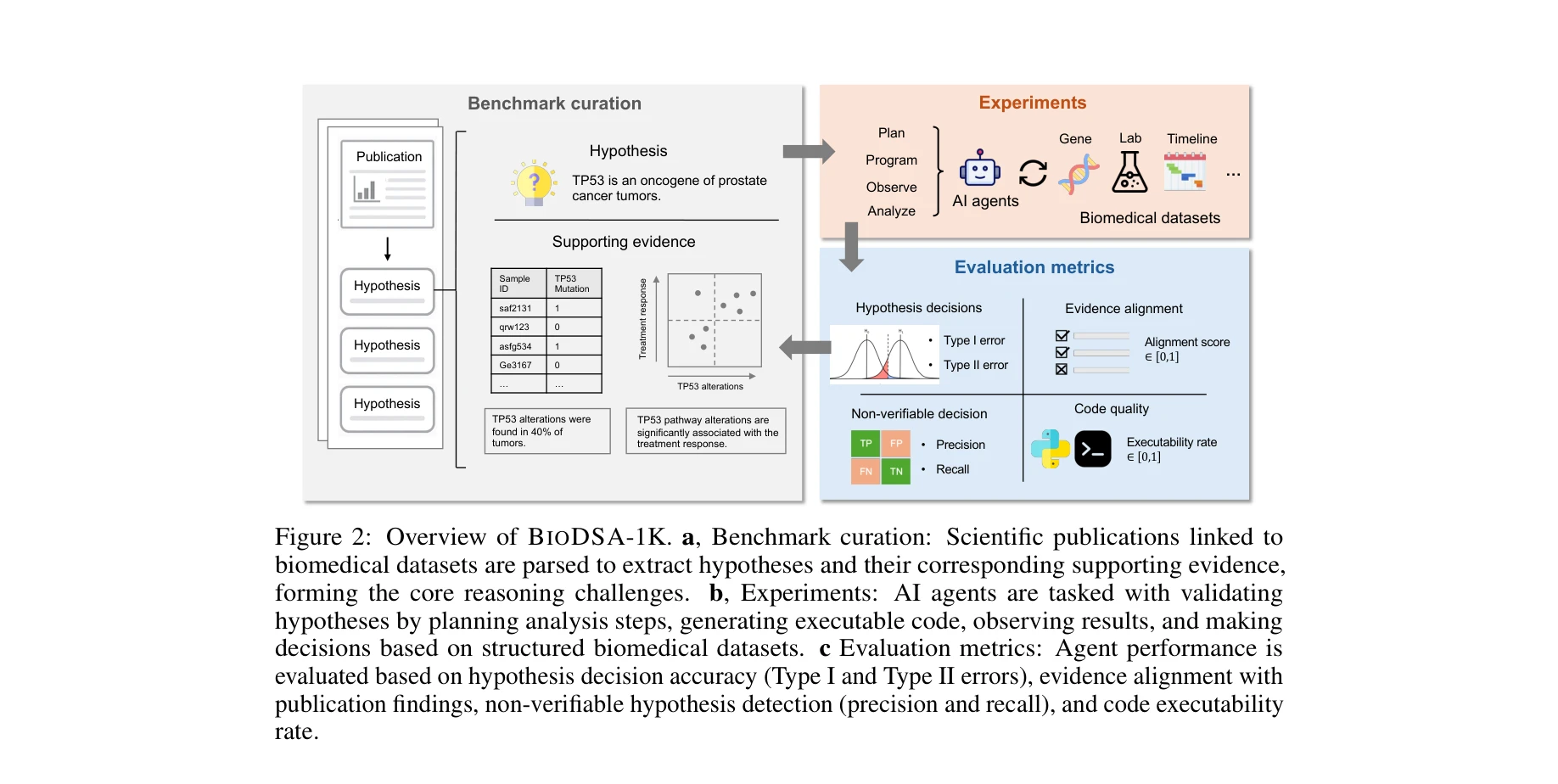
Essence
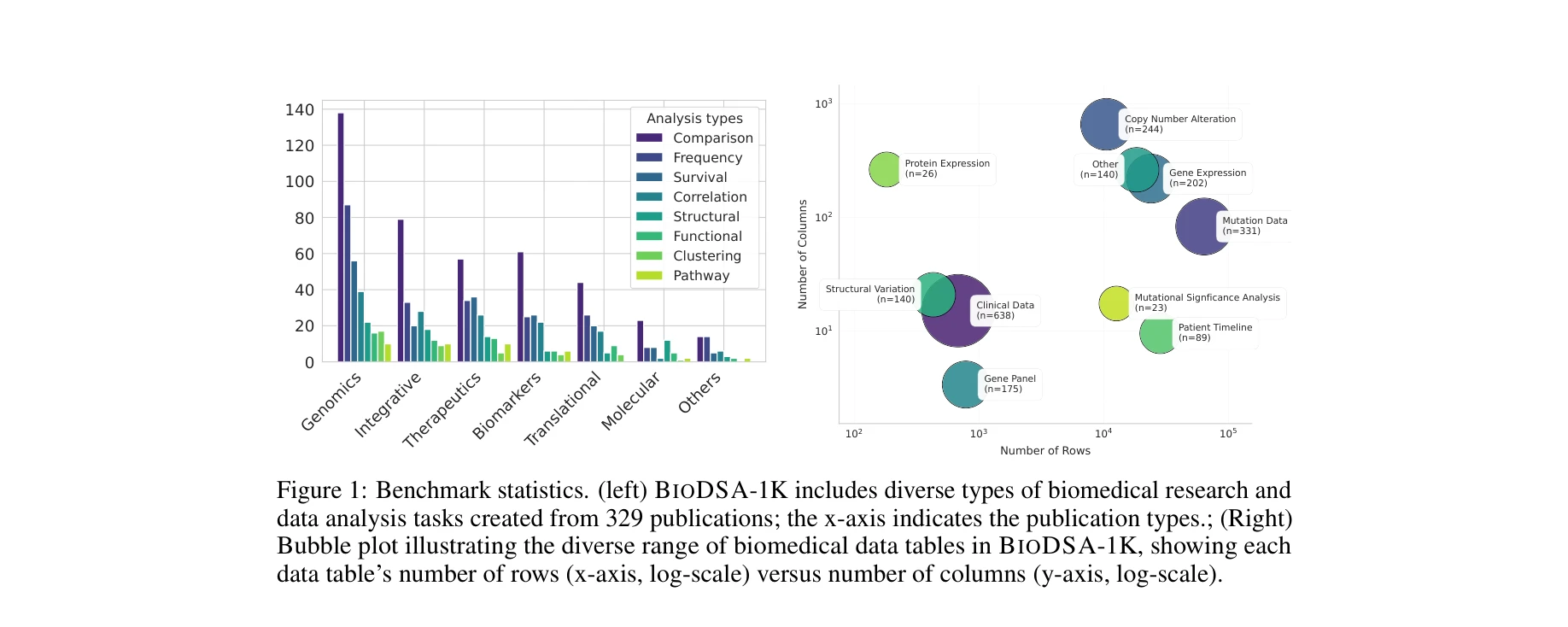
BIODSA-1K의 벤치마크 통계: 329개 논문에서 추출된 다양한 생의학 연구 유형과 데이터 분석 과제들, 데이터 테이블의 행과 열의 범위를 보여주는 버블 플롯
본 논문은 생의학 연구에서 AI 에이전트의 가설 검증 능력을 평가하기 위해 1,029개의 가설 중심 과제와 1,177개의 분석 계획으로 구성된 BIODSA-1K 벤치마크를 제시한다. 329개 출판 논문에서 추출된 이 벤치마크는 실제 연구 워크플로우를 반영하며, 검증 불가능한 가설 사례를 포함하여 현실적인 데이터 과학 시나리오를 평가한다.