Essence

PROTEUS의 반복적 개선 프레임워크(a)와 상세한 작업 프로세스(b). 데이터 설명, 연구 목표 계획, 워크플로우 계획, 도구 실행, 결과 해석의 순환 구조
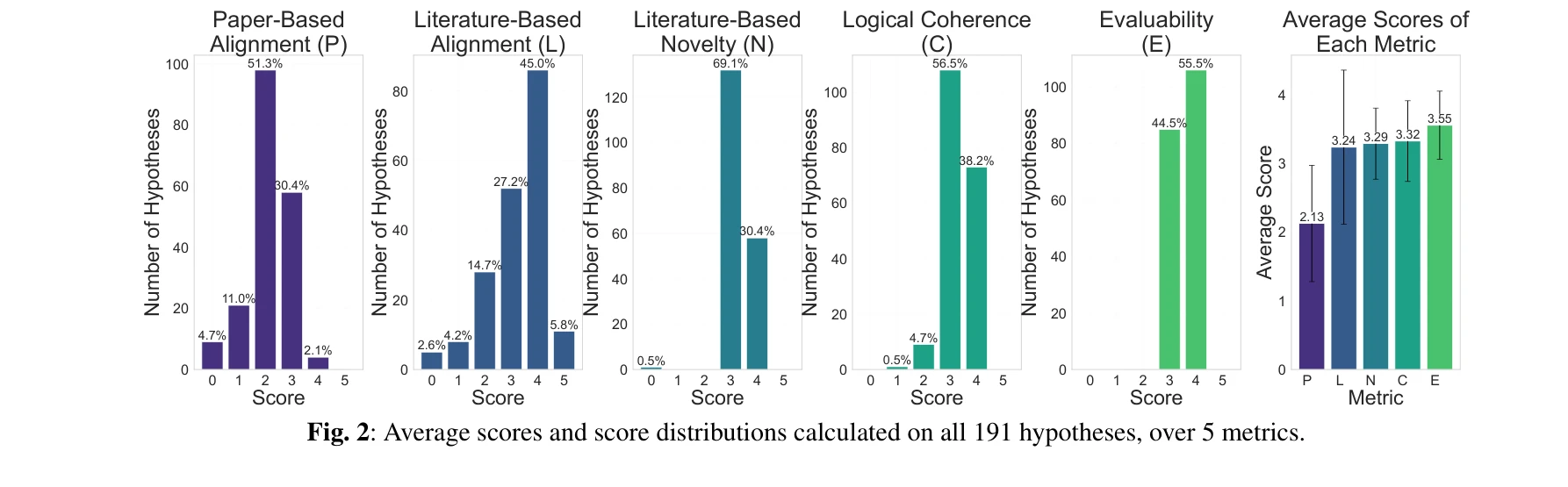
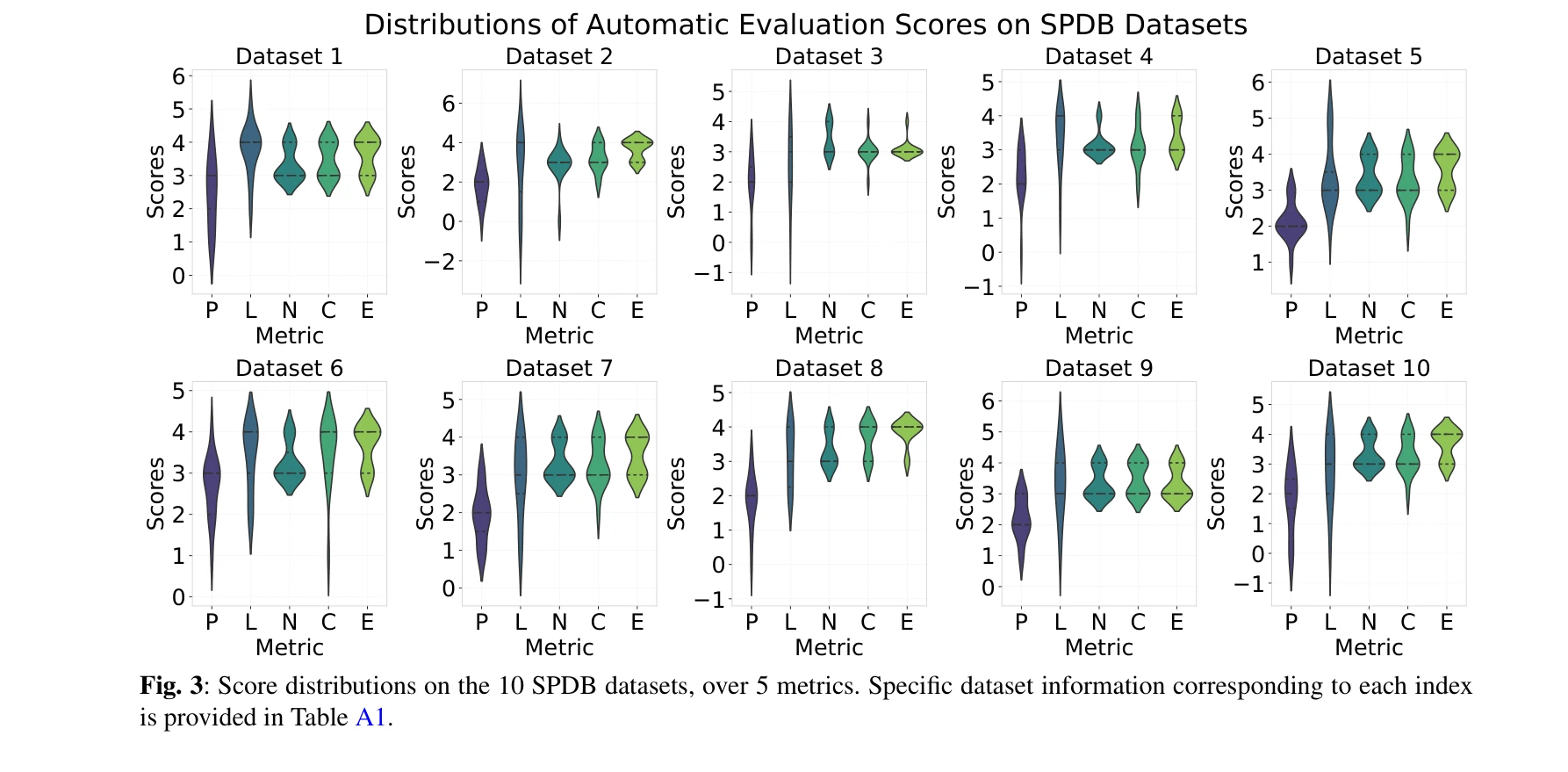
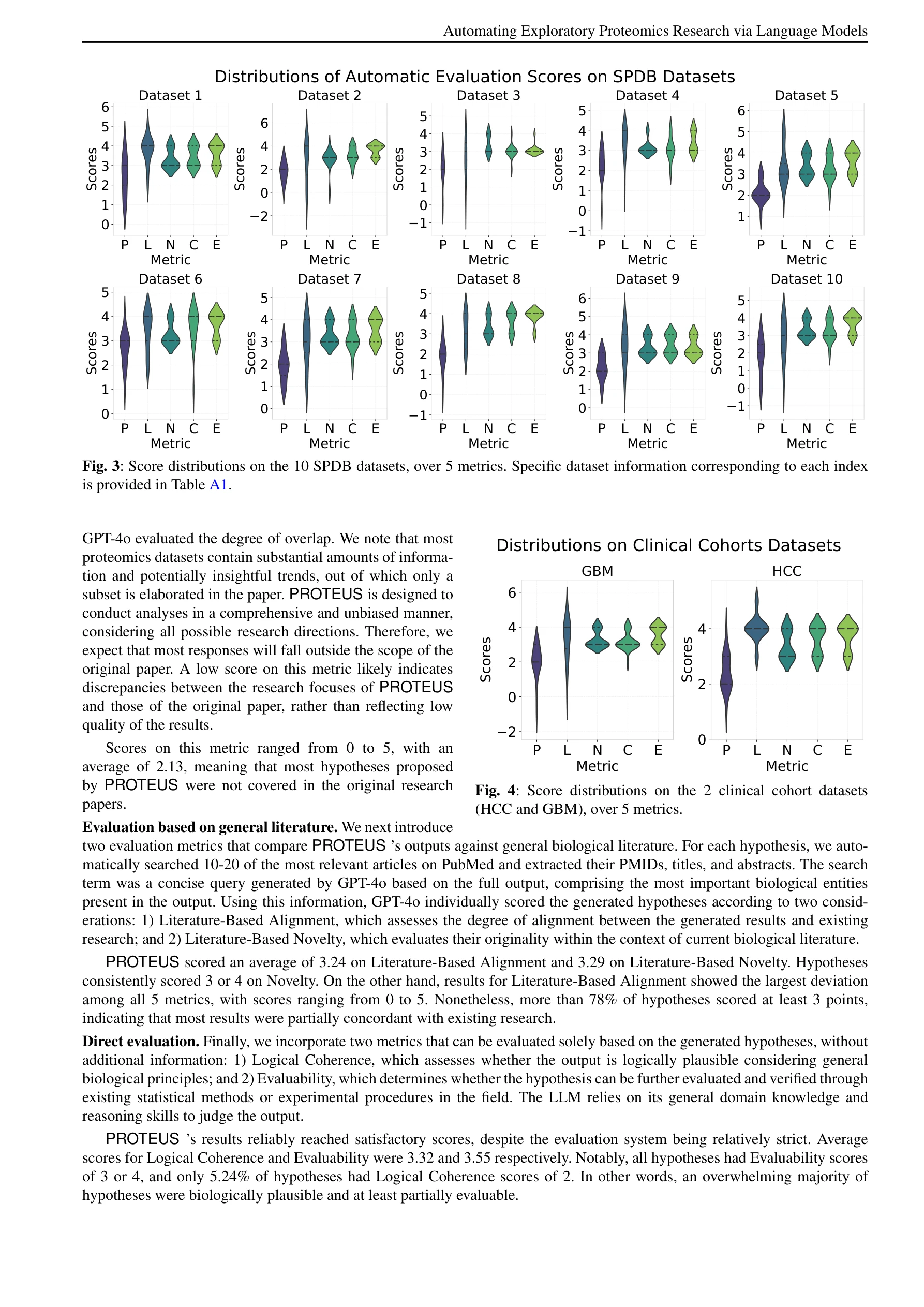
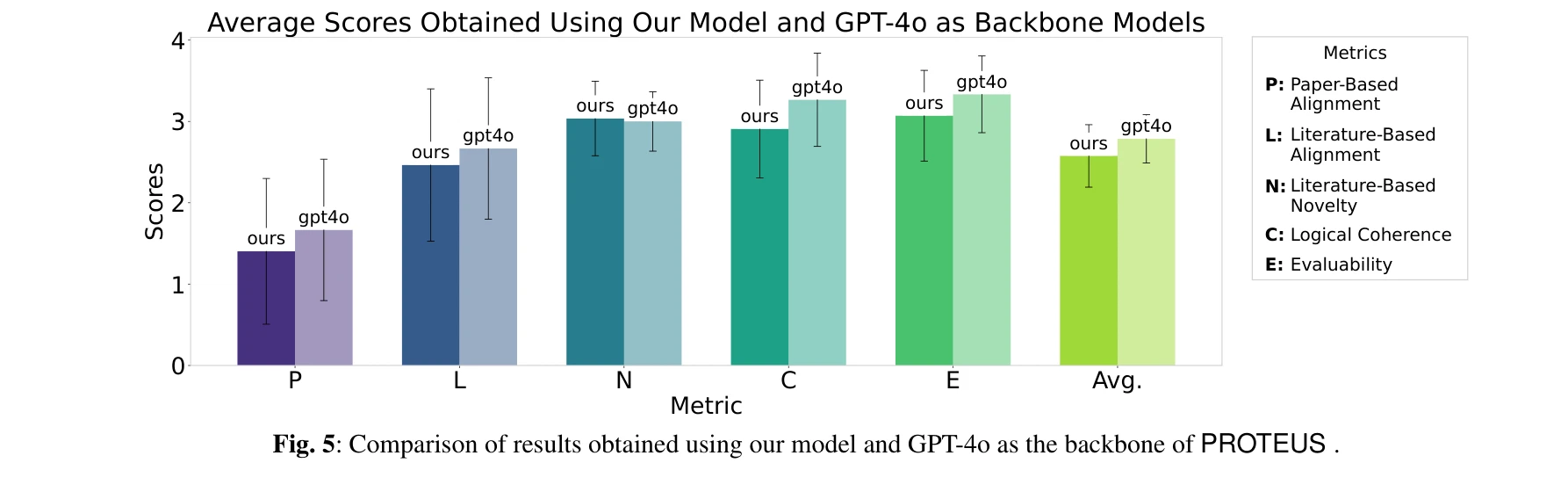
본 논문은 대규모 언어모델(LLM)을 활용하여 원본 단백질체학(proteomics) 데이터로부터 자동으로 과학적 발견을 수행하는 PROTEUS 시스템을 제시한다. 인간의 개입 없이 계층적 계획 수립, 생물정보학 도구 실행, 반복적 분석 워크플로우 정제를 통해 고품질의 생물학적 가설을 생성한다.