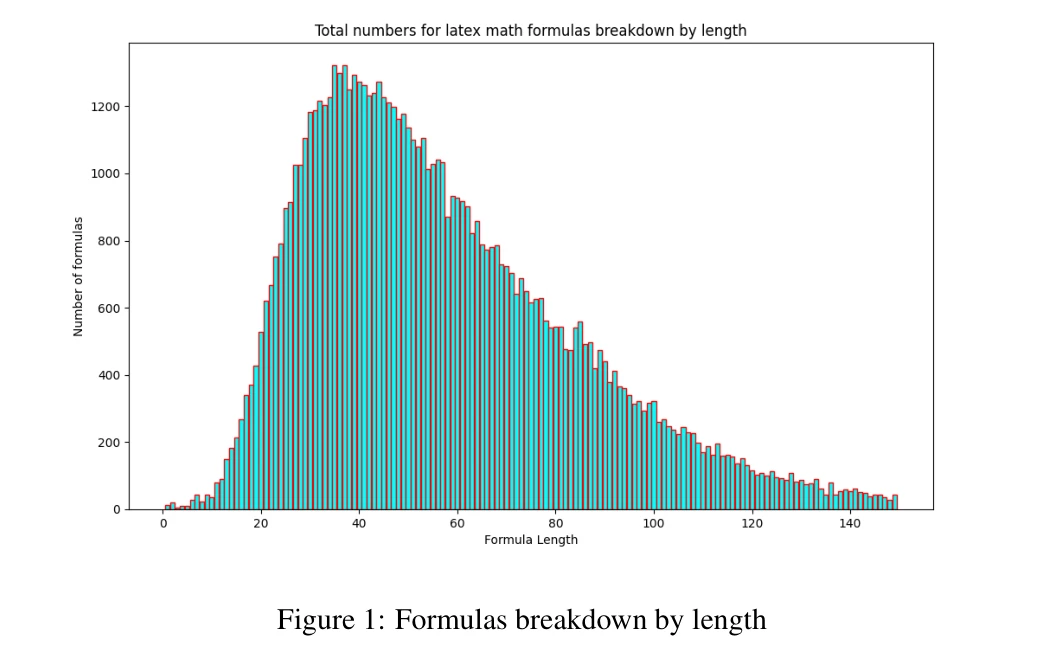
How
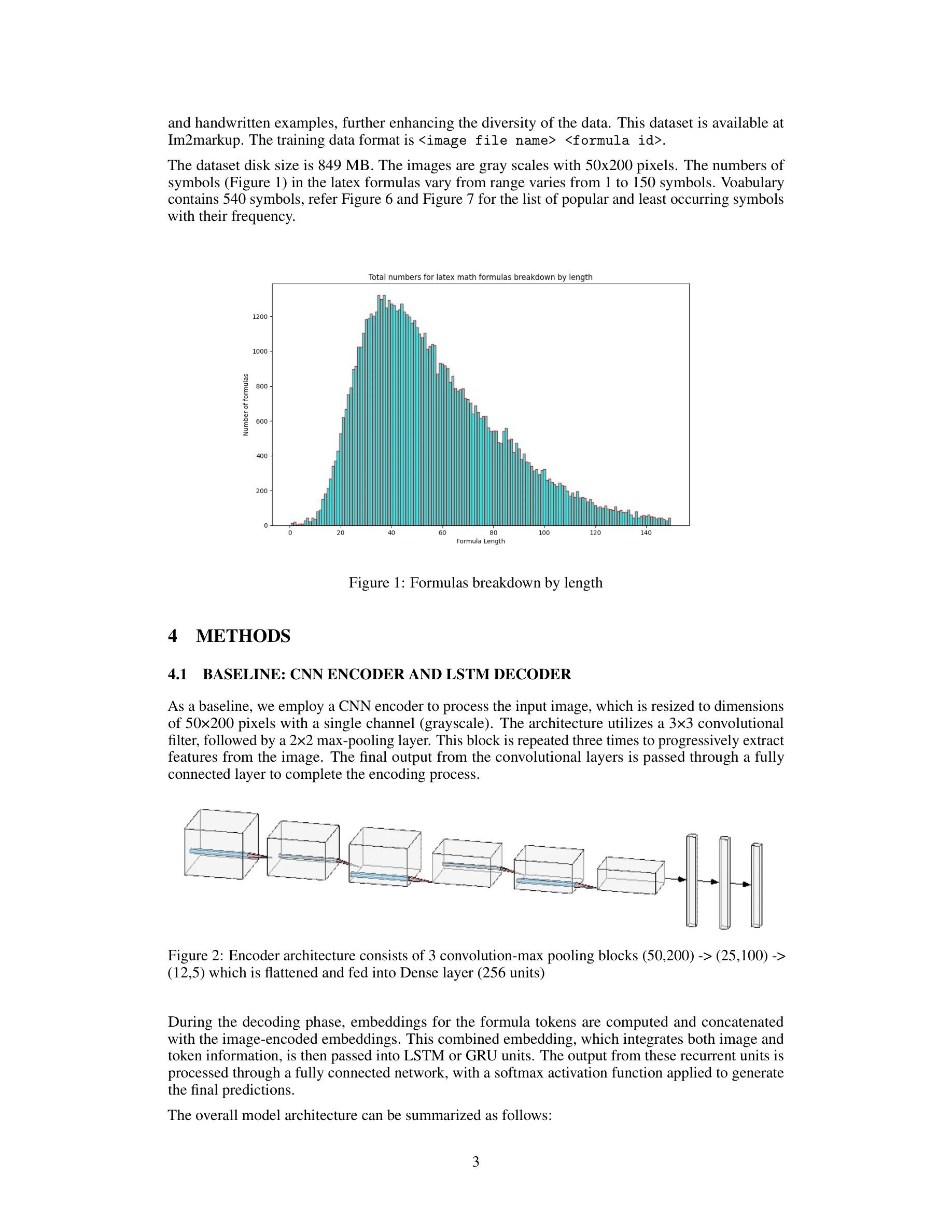
Figure 2: CNN 기준 모델 인코더 구조 (50,200) → (25,100) → (12,50) 차원 축소
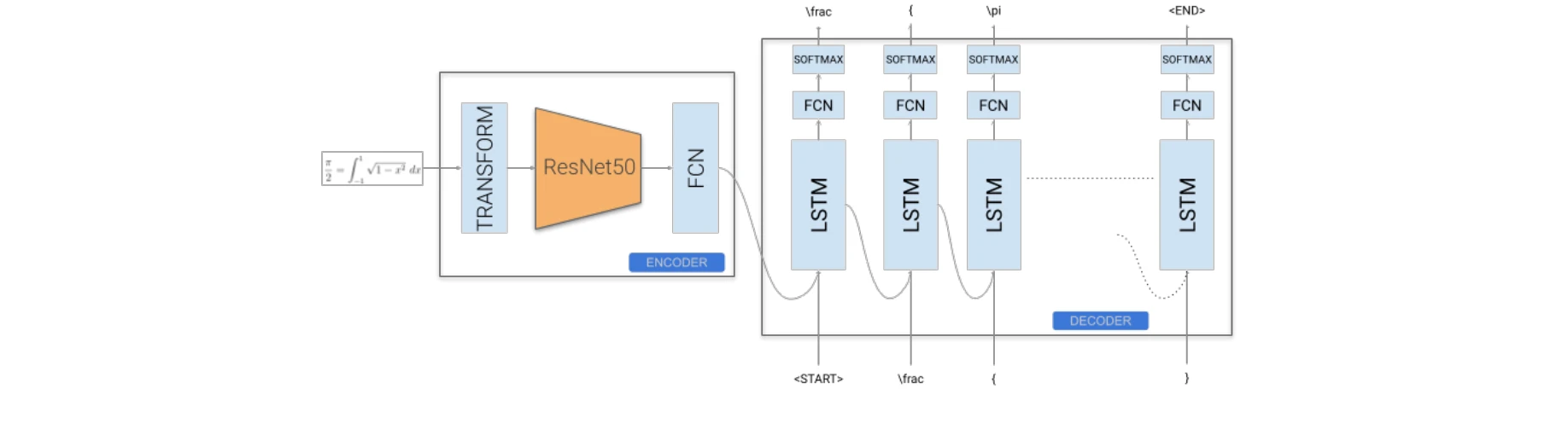
Figure 3: ResNet50 사전학습 모델 인코더와 LSTM 디코더
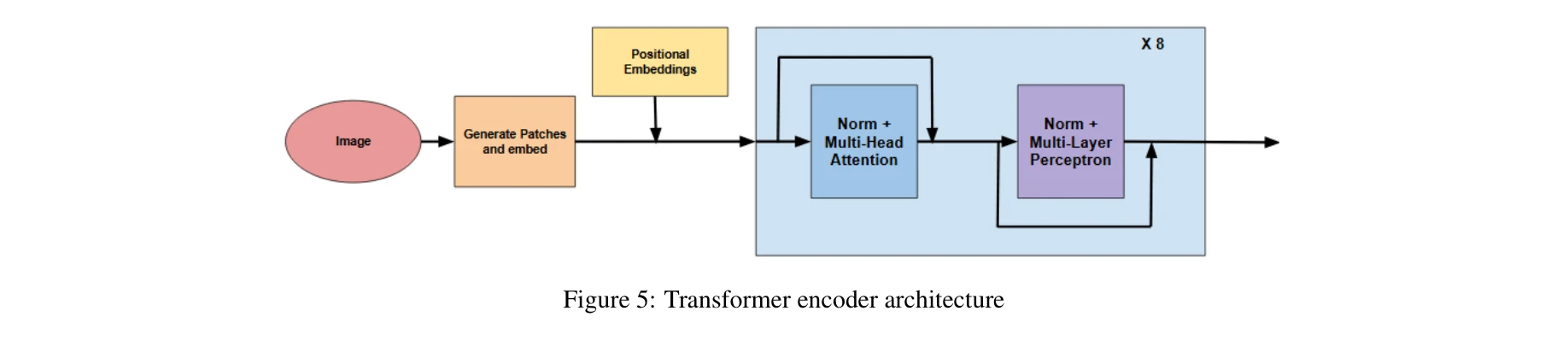
Figure 5: 트랜스포머 인코더 아키텍처 (8개 레이어, 4개 주의 헤드)
기준 모델 (CNN-LSTM)
- 3×3 합성곱 필터와 2×2 최대 풀링을 3회 반복하는 인코더
- 토큰 임베딩과 이미지 인코딩을 결합하여 LSTM/GRU에 입력
- 최종 완전연결층에서 소프트맥스 활성화로 예측 생성
ResNet50-LSTM 개선 모델
- 사전학습된 ResNet50을 인코더로 활용 (98 MB, ImageNet 사전학습)
- 그레이스케일 입력을 RGB로 변환 (
tf.image.grayscale_to_rgb) 후 254×254로 리사이징
- 풍부한 특성 추출 능력으로 기준 모델 개선
Vision Transformer 아키텍처
인코더:
- 이미지를 10×10 픽셀 패치 100개로 분할
- 선형 임베딩과 위치 임베딩 적용
- 8개 트랜스포머 레이어 (각 4개 주의 헤드)
- 각 레이어에 2,048→1,024 유닛의 MLP 블록 포함
디코더:
- 4개 주의 레이어 (교차-주의 및 자기-주의 각 8개 헤드)
- 교차-주의: 이미지의 관련 영역 식별
- 자기-주의: 생성 시퀀스의 의존성 모델링
학습 설정
- 데이터: Im2latex-100k, Im2latex-230k (총 200,000개 샘플, 849 MB)
- 입력: 50×200 픽셀 그레이스케일 이미지
- 어휘: 540개 심볼
- 배치 크기: CNN-LSTM, ResNet-LSTM은 128, ViT는 64
- 최적화: CNN/ResNet은 Adam(lr=0.001), ViT는 AdamW(lr: 1e-4→1e-6 감쇠)
- 조기 중단: 인내도 10 에포크
- 학습 시간: 1.5~2시간 (AWS G6.xlarge GPU)
Evaluation
총평: 이 논문은 Vision Transformer를 필기 수학식 인식 작업에 체계적으로 적용하고 기존 CNN-RNN 기준 모델과 비교한 실용적 연구이다. 아키텍처 설계와 구현은 견고하며 오픈 소스 공개로 재현성을 확보했다. 그러나 완성되지 않은 결과 분석 섹션, 정량적 성능 수치의 부재, 그리고 아키텍처 혁신보다는 기존 기법의 응용에 머물러 있다는 점이 학술적 기여도를 제한한다. 추가적으로 더 높은 해상도 입력과 실제 필기 데이터 실험이 필요하며, 오류 사례 분석을 통한 통찰력 제공이 논문의 가치를 크게 높일 수 있을 것으로 예상된다.