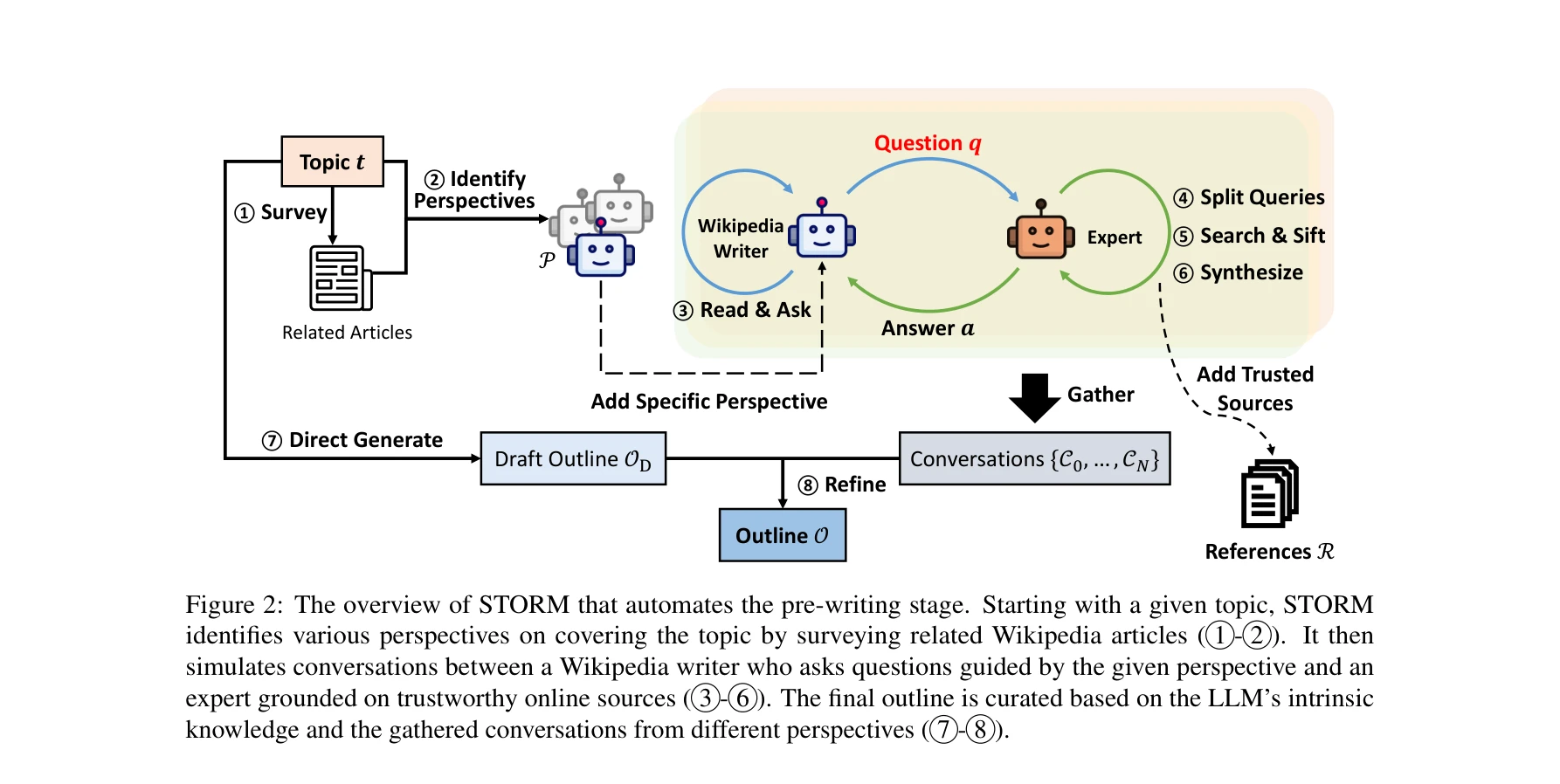
Essence

STORM은 Wikipedia와 같은 장문의 기사를 처음부터 작성할 때 필요한 사전 작성 단계(pre-writing stage)를 자동화한다. 다양한 관점의 질문 제시를 통해 주제를 연구하고 아웃라인을 생성한다.
본 논문은 대규모 언어모델(LLM)을 활용하여 Wikipedia 수준의 장문 기사를 처음부터 작성하는 문제를 다루며, 특히 사전 작성 단계에서의 주제 연구와 아웃라인 생성에 초점을 맞춘다. STORM(Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking) 시스템을 제안하여 다양한 관점에서의 질문 생성과 정보 수집을 통해 체계적인 아웃라인을 자동으로 구성할 수 있음을 보인다.