Essence
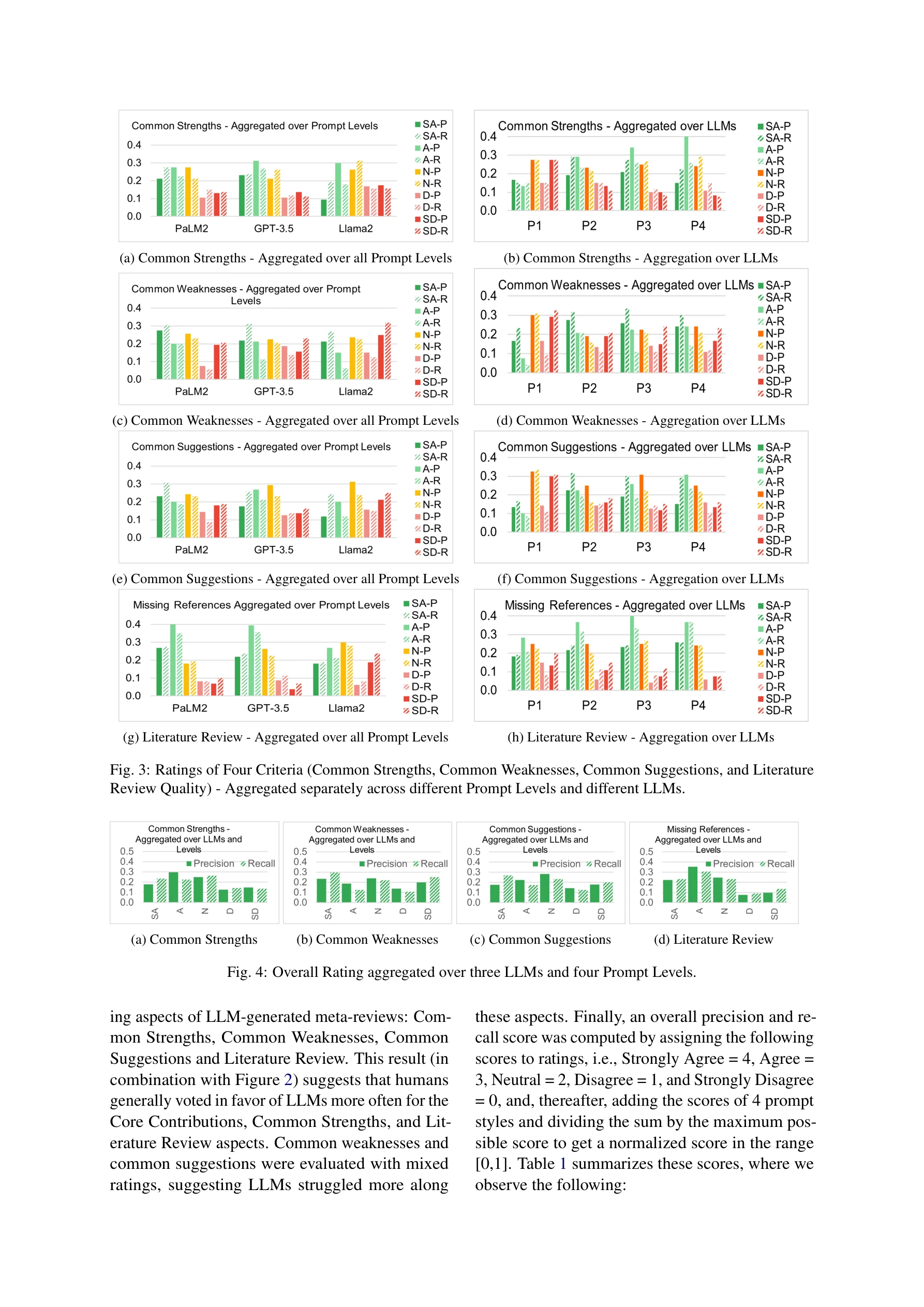
Fig. 4: Overall Rating aggregated over three LLMs and four Prompt Levels.
본 논문은 LLM(GPT-3.5, PaLM2, LLaMA2)이 학술 논문의 피어 리뷰 의견들을 종합하여 메타리뷰 초안 작성을 지원할 수 있는지 연구한 사례 연구이다.
저자: Lan Luo, Dongyijie Primo Pan, Junhua Zhu, Muzhi Zhou, Pan Hui | 날짜: 2024 | URL: https://arxiv.org/abs/2402.15589
Fig. 4: Overall Rating aggregated over three LLMs and four Prompt Levels.
본 논문은 LLM(GPT-3.5, PaLM2, LLaMA2)이 학술 논문의 피어 리뷰 의견들을 종합하여 메타리뷰 초안 작성을 지원할 수 있는지 연구한 사례 연구이다.
Fig. 4: Overall Rating aggregated over three LLMs and four Prompt Levels.
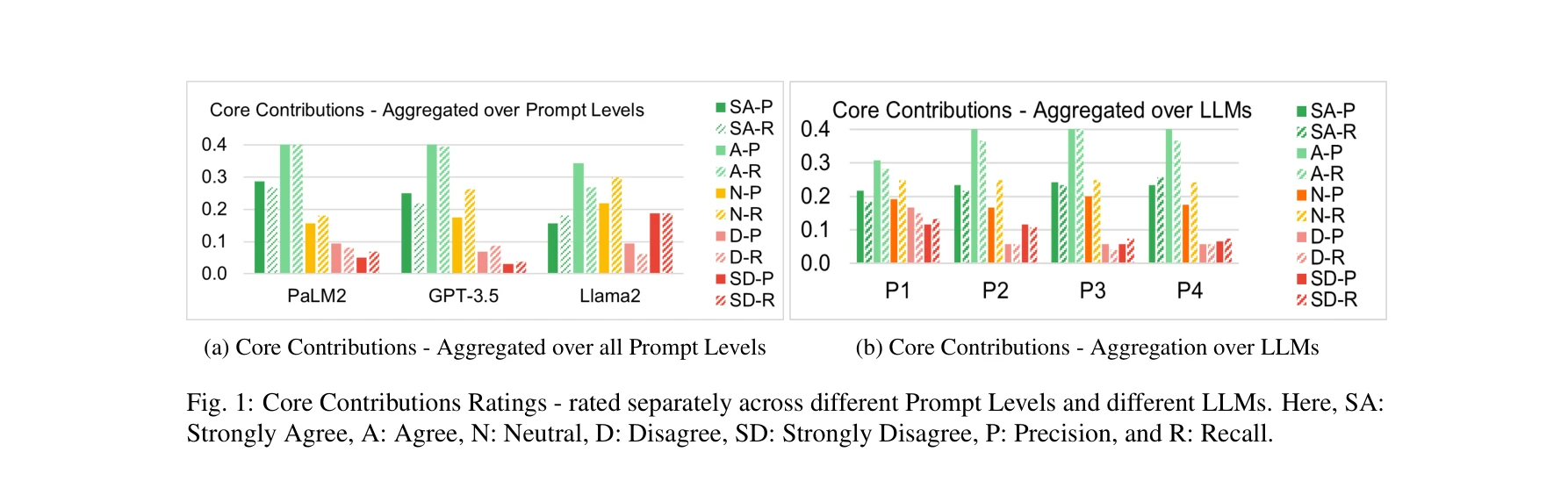
Fig. 1: Core Contributions Ratings - rated separately across different Prompt Levels and different LLMs. Here, SA:
총평: 본 논문은 표준화된 프롬프팅 분류체계를 적용하여 메타리뷰 작성 지원 작업에 대한 LLM의 성능을 최초로 체계적으로 비교 분석했으며, 대규모 정성적 평가를 통해 LLM 자동 평가의 신뢰성 문제를 밝혀냈다는 점에서 학술 출판 프로세스 자동화 연구에 유의미한 기여를 한다.