저자: Zhihao Fan, Jialong Tang, Wei Chen, Siyuan Wang, Zhongyu Wei, Jun Xie, Fei Huang, Jingren Zhou (Alibaba Inc., Huazhong University of Science and Technology, Fudan University) | 날짜: 2024 | DOI: arXiv:2402.09742
Essence
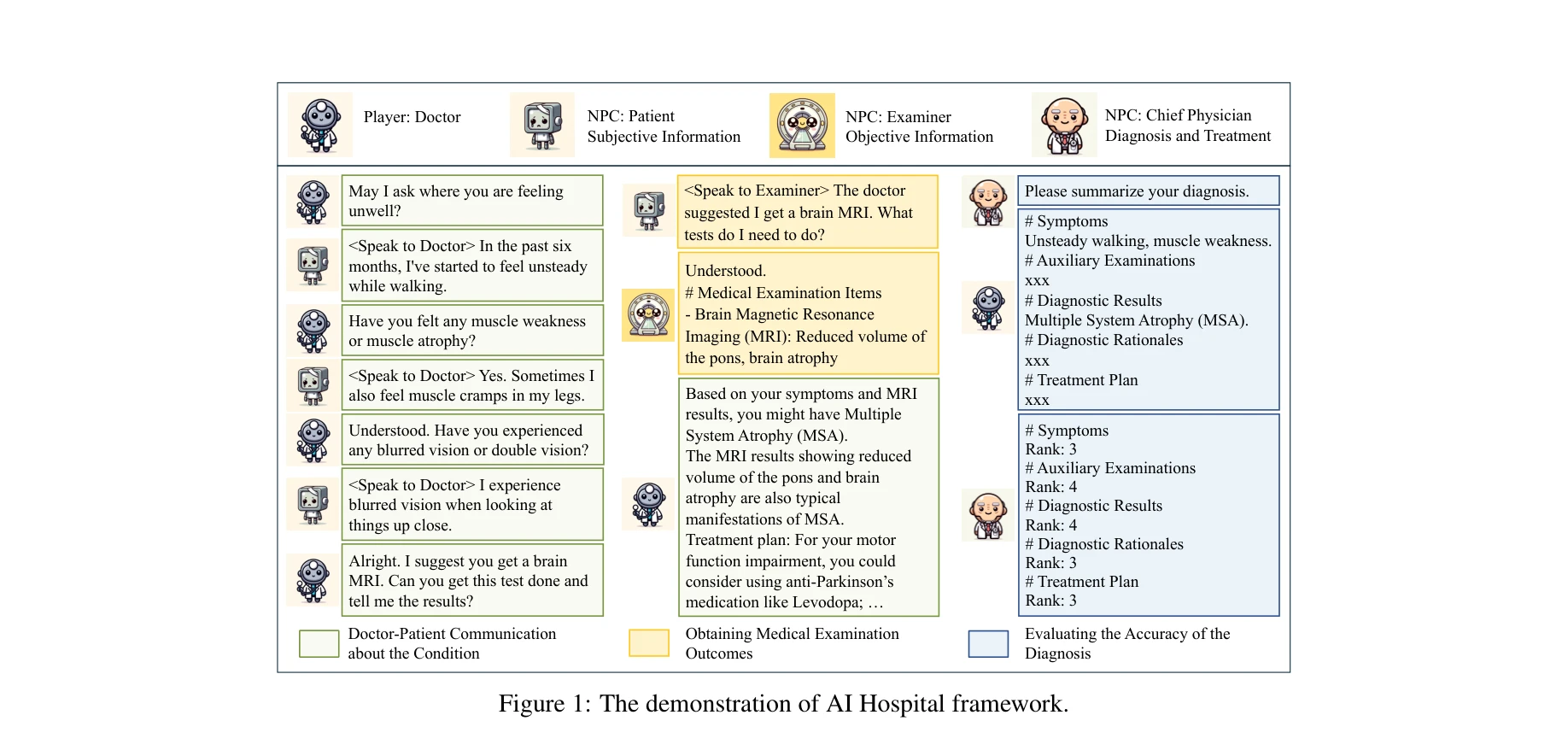
AI Hospital 프레임워크의 다중 에이전트 상호작용 시뮬레이션: 의사(플레이어)가 환자, 검사관, 과장과 다중 턴 대화를 통해 진단하는 동적 의료 상호작용 환경
대규모 언어 모델(LLM)이 의료 질문 답변 벤치마크에서 우수한 성능을 보이지만, 실제 의료 현장의 복잡한 의사-환자 상호작용을 반영하지 못한다. 이 논문은 다중 에이전트 의료 상호작용 시뮬레이터인 AI Hospital을 제안하고, 현실적인 임상 진단 시나리오에서 LLM의 성능 격차를 평가한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: AI Hospital은 의료 AI의 현실적 성능 평가를 위해 다중 에이전트 시뮬레이션과 고품질 의료 기록을 결합한 의미 있는 프레임워크이며, 현존 LLM이 벤치마크와 실제 임상 상황 사이의 상당한 격차(50% 이하)를 갖고 있음을 정량적으로 입증하였으나, 중국 특화성과 한계 분석의 깊이 부족이 일반화 가능성을 제한한다.