Essence
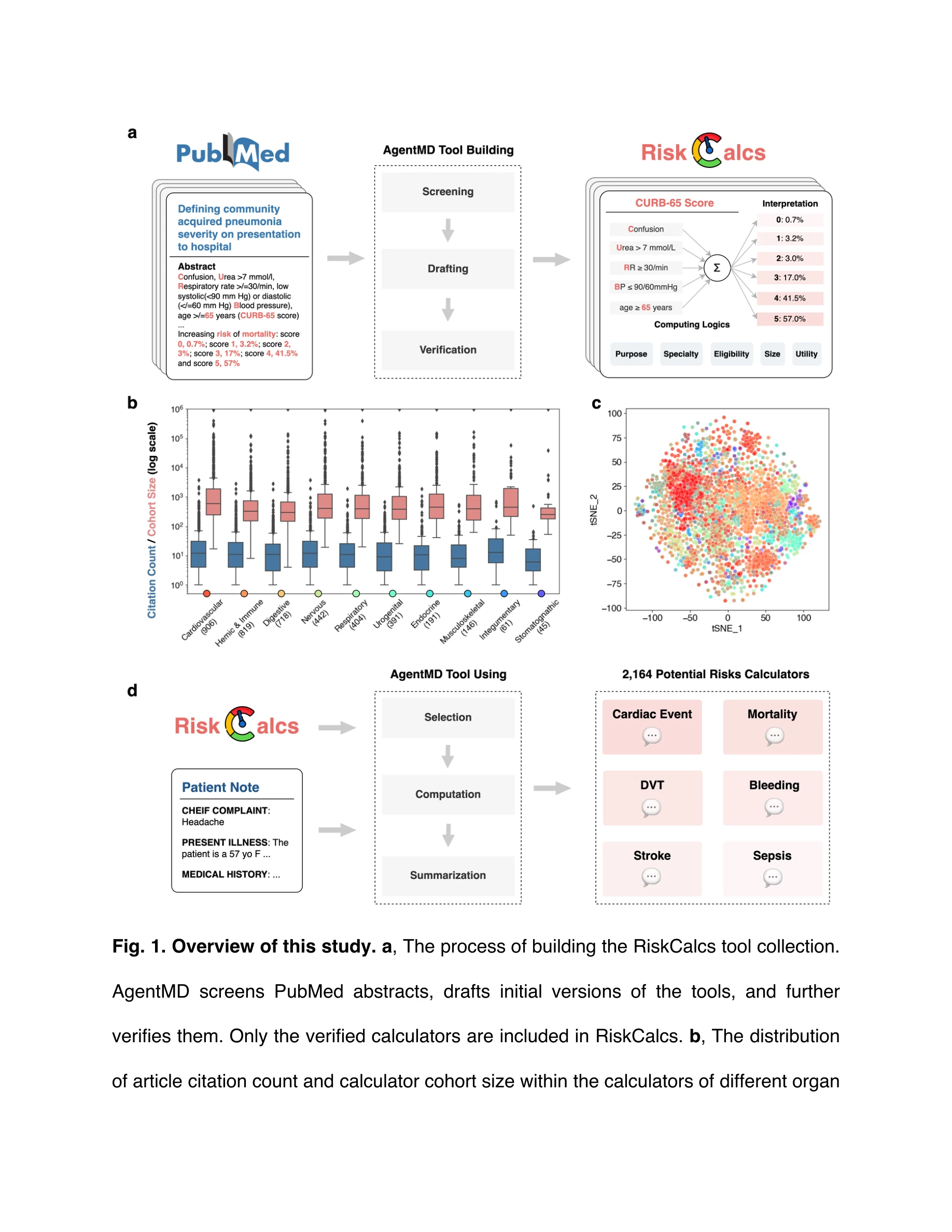
그림 1. 연구 개요: (a) RiskCalcs 도구 모음 구축 프로세스, (b) 장기 시스템별 계산기 분포, (c) 도구의 의미적 표현 t-SNE 시각화, (d) 환자 노트에 RiskCalcs 적용 프로세스
본 논문은 대규모 언어모델(LLM)을 활용하여 PubMed 문헌으로부터 2,164개의 임상 계산기(RiskCalcs)를 자동으로 큐레이션하고, 이를 환자 기록에 적용하는 의료 언어 에이전트 AgentMD를 제시한다. 기존 수동 큐레이션의 확장성 문제를 극복하면서 80% 이상의 정확도를 달성하고, 기존 GPT-4 체인-오브-소트(Chain-of-Thought) 방식(40.9%)을 크게 능가한다(87.7%).

