Achievement
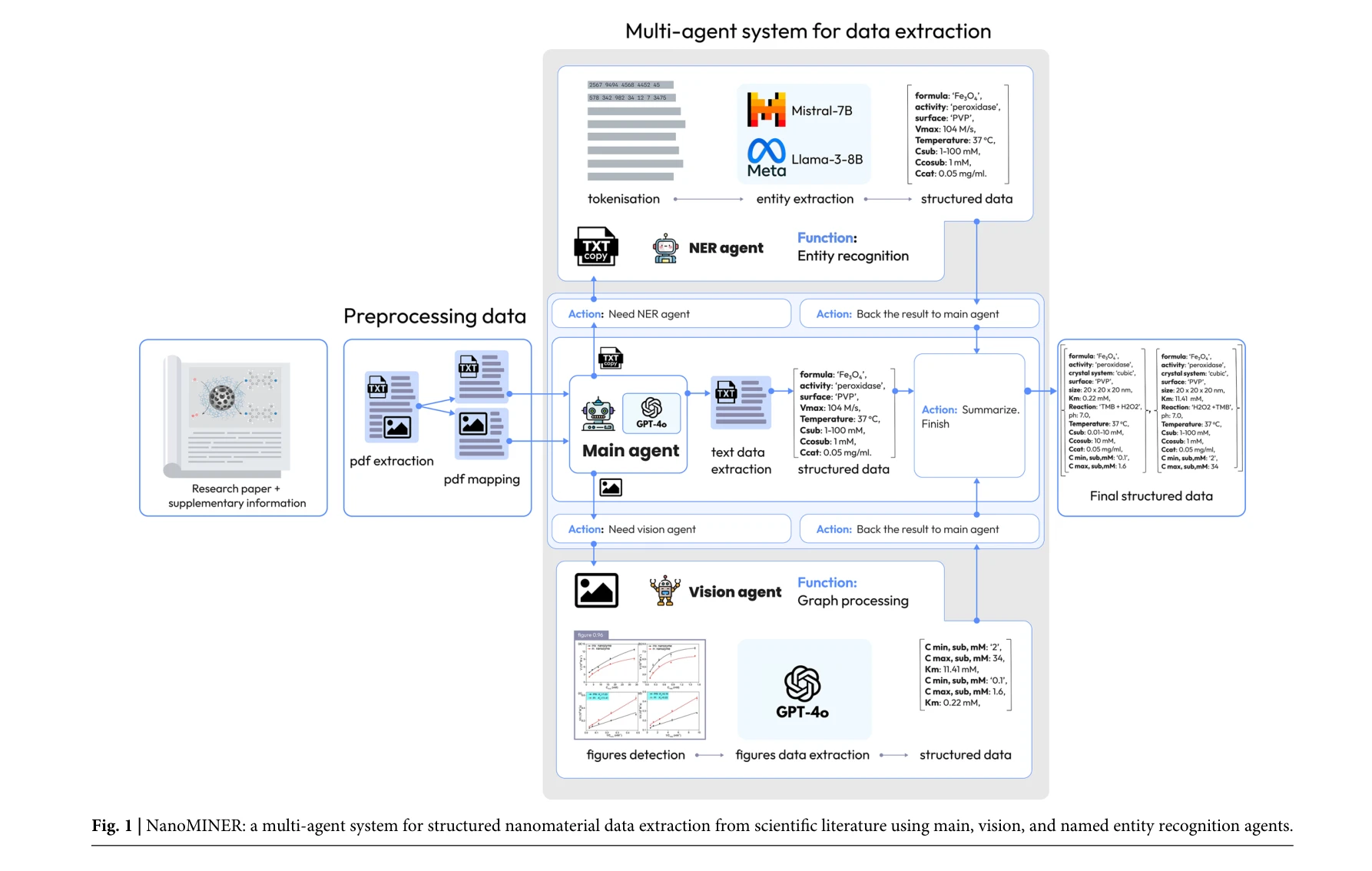
nanoMINER: 다중 에이전트 시스템의 구조로 PDF 입력부터 구조화된 데이터 출력까지의 전체 파이프라인 표시
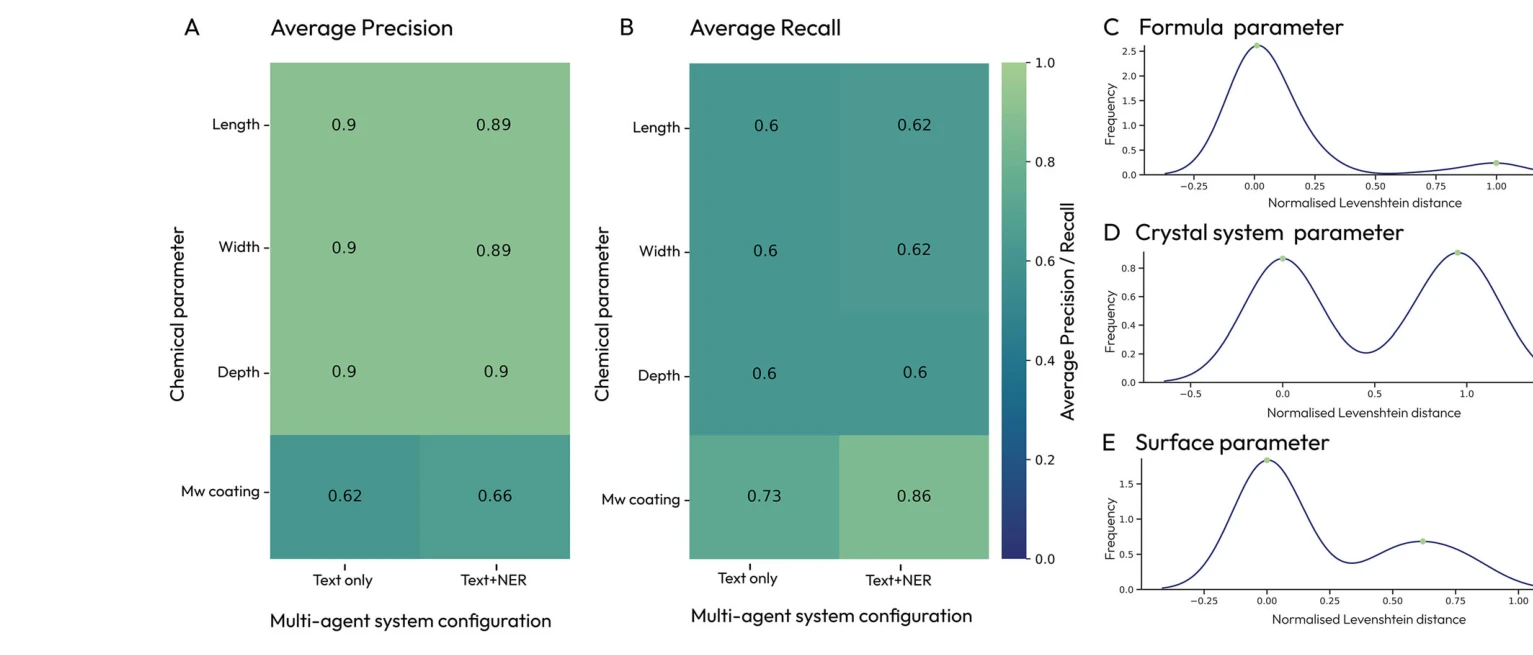
- 나노물질 데이터 추출: 19개 논문의 25개 실험에서 화학식, 결정계, 크기, 표면 개질 등의 매개변수를 추출했으며, 화학식과 코팅 분자에서 정규화된 Levenshtein 거리가 거의 0에 가까운 수준(~0.0)의 정확도 달성, 코팅 분자 무게 추출에서 0.66의 정밀도 달성
- 나노자임 데이터 추출: Km, Vmax, 최소/최대 기질 농도(Cmin, Cmax)에 대해 0.96 이상의 정밀도, 특히 kinetic parameter에서 0.98의 거의 완벽에 가까운 정밀도 달성
- 기준 모델과의 비교: 더 오래된 GPT-4o를 Main agent로 사용함에도 불구하고, 최신 GPT-4.1과 추론 모델(o3-mini, o4-mini)을 포함한 모든 기준 LLM을 평균 정밀도, 재현율, F1 스코어에서 지속적으로 상회
- 암묵적 정보 추출: 화학식으로부터 결정계를 추론하는 능력을 시연하여, 명시적 정보뿐만 아니라 암묵적 데이터도 추출 가능함을 입증