저자: Junting Zhou, Wang Li, Yiyan Liao, Nengyuan Zhang, Tingjia Miao, Zhihui Qi, Yuhan Wu, Tong Yang (Peking University) | 날짜: 2025 | DOI: 10.48550/arXiv.2506.13784
Essence
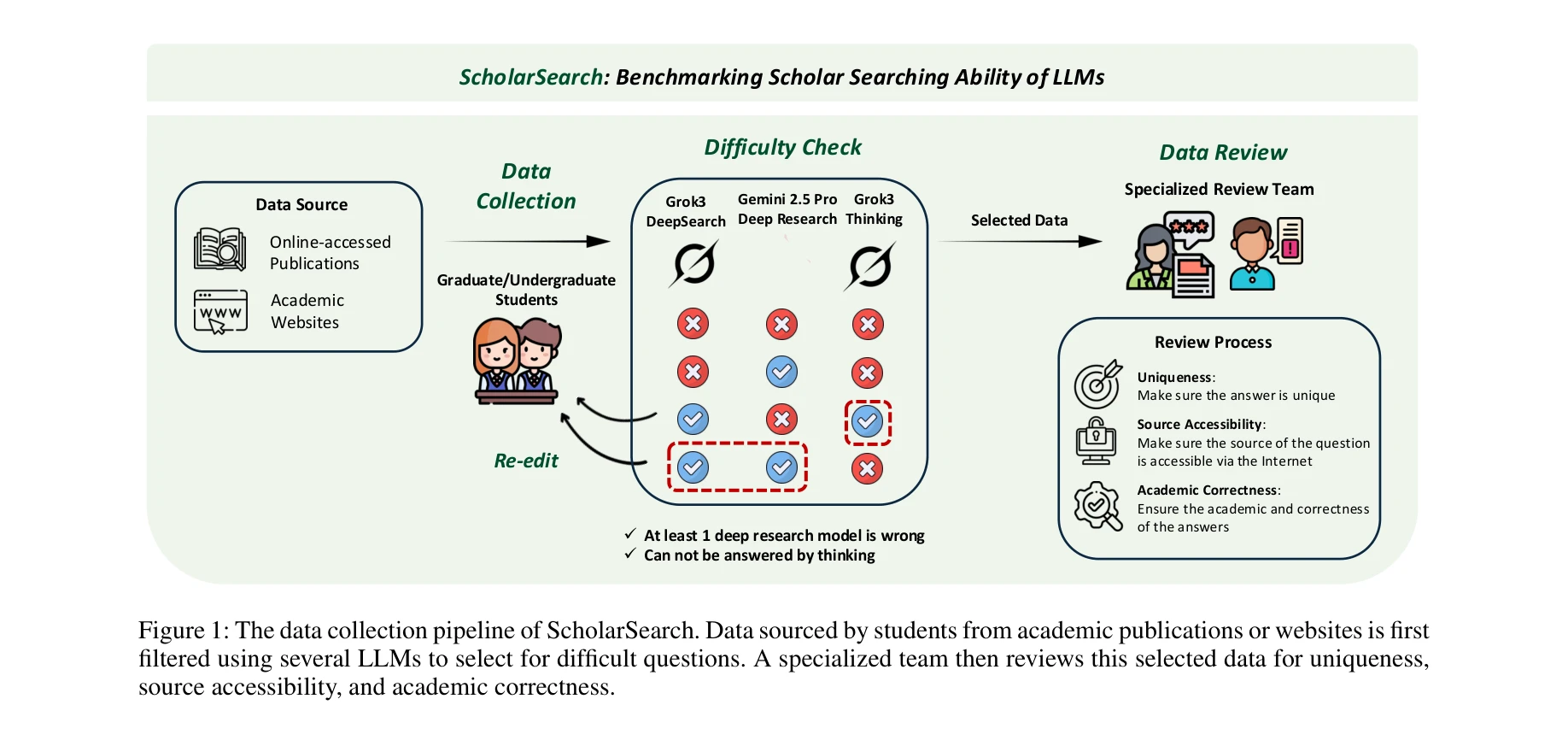
ScholarSearch의 데이터 수집 파이프라인: 학생들이 수집한 데이터를 여러 LLM으로 필터링한 후 전문 검토팀이 유일성, 출처 접근성, 학술적 정확성을 검증
본 논문은 LLM의 복잡한 학술 정보 검색 능력을 평가하기 위한 첫 번째 전문 벤치마크인 ScholarSearch를 제시한다. 기존의 학술 벤치마크(MMLU, GPQA)나 일반 웹 검색 벤치마크(BrowseComp)로는 충분하지 않은 깊이 있는 학술 연구 검색 능력을 측정한다.
Evaluation
총평: ScholarSearch는 LLM의 학술 정보 검색 능력을 평가하기 위한 실질적이고 도전적인 벤치마크로서, 기존 벤치마크의 공백을 효과적으로 메운다. 데이터 수집의 엄격성과 학문 분야의 다양성이 강점이나, 규모 확장과 평가 메커니즘의 정교화를 통해 더욱 강력한 평가 도구로 발전할 수 있는 잠재력을 보유하고 있다.

