Essence
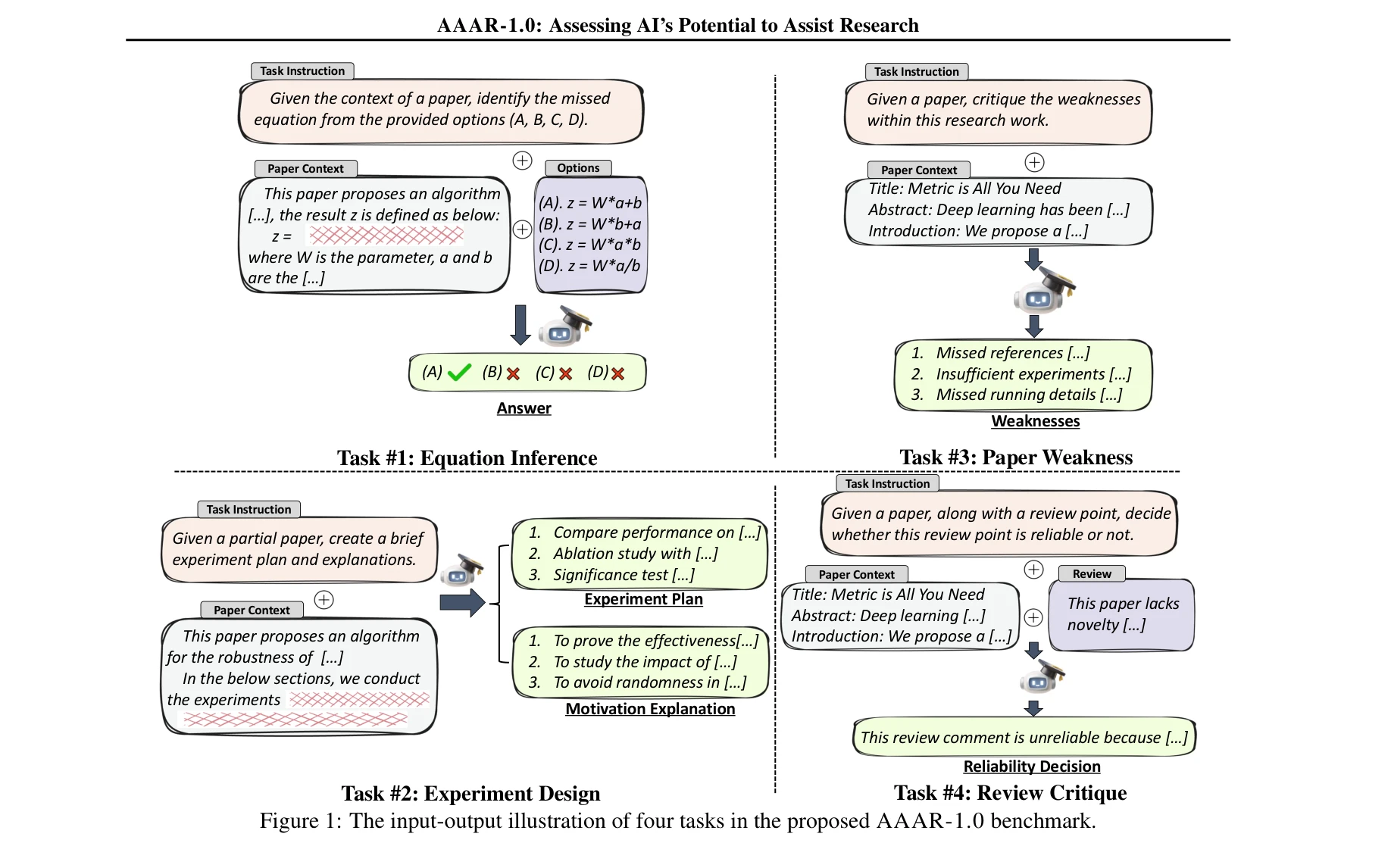
그림 1: AAAR-1.0 벤치마크의 4가지 작업에 대한 입출력 예시
본 논문은 대규모 언어모델(LLM)이 연구 작업을 얼마나 효과적으로 지원할 수 있는지 평가하기 위한 벤치마크 AAAR-1.0을 제시한다. 방정식 추론, 실험 설계, 논문 약점 식별, 리뷰 비판의 4가지 전문가급 AI 연구 작업을 통해 LLM의 지식 기반과 추론 능력을 종합적으로 평가한다.
저자: Renze Lou et al. | 날짜: 2025 | DOI: N/A
그림 1: AAAR-1.0 벤치마크의 4가지 작업에 대한 입출력 예시
본 논문은 대규모 언어모델(LLM)이 연구 작업을 얼마나 효과적으로 지원할 수 있는지 평가하기 위한 벤치마크 AAAR-1.0을 제시한다. 방정식 추론, 실험 설계, 논문 약점 식별, 리뷰 비판의 4가지 전문가급 AI 연구 작업을 통해 LLM의 지식 기반과 추론 능력을 종합적으로 평가한다.

그림 2: 데이터 구축 과정 개요
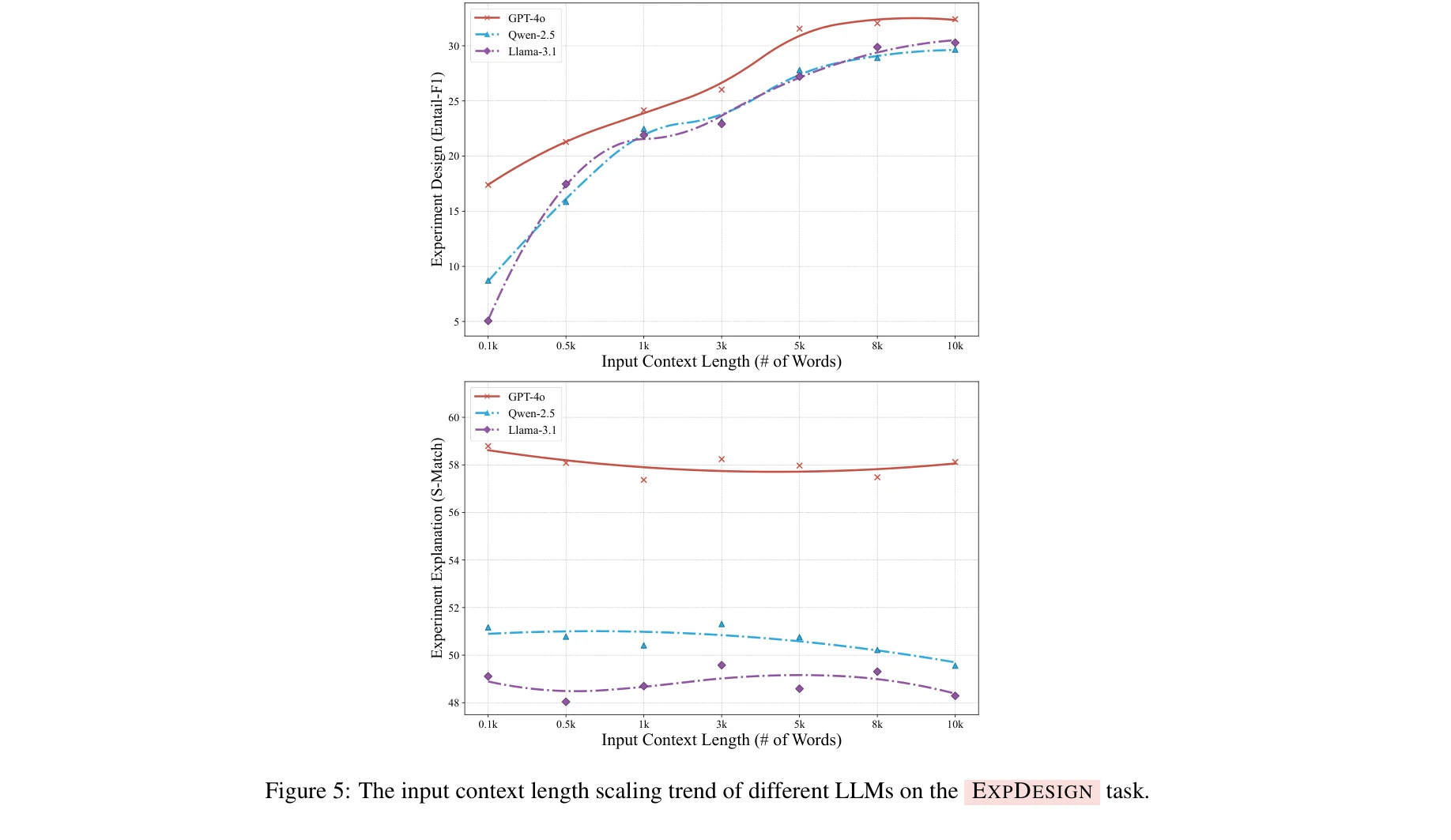
그림 5: EXPDESIGN 작업에서 다양한 LLM의 문맥 길이 스케일링 추이
총평: 본 논문은 AI가 전문적 연구 활동을 얼마나 효과적으로 지원할 수 있는지 체계적으로 평가하기 위한 고품질 벤치마크를 제시했으며, 현재 LLM의 명확한 한계를 드러냄으로써 학계에 의미 있는 기여를 한다. 다만 특정 분야 편중 극복과 실제 개선 방안 제시를 통해 더욱 완성도 높은 연구로 발전할 여지가 있다.