- Matplotlib 객체지향 방식은 훌륭합니다.
- 객체를 섬세하게 제어할 수 있고, 시각화 함수를 만들기도 좋습니다.
- 데이터 정리부터 객체지향 방식으로 그림을 그리는 예제를 만들어 보았습니다.
1. 목표
우리나라 인구 데이터로부터 이런 그림을 그릴 것입니다.
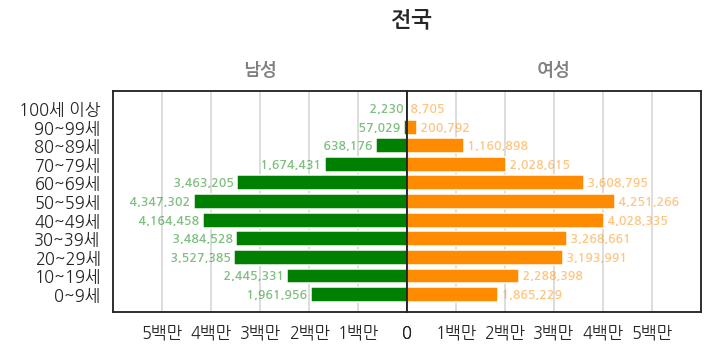
한번 그리고 말 것이 아닙니다.
시나 도 이름을 입력하면 데이터만 바뀐 같은 형식의 그림을 찍어낼 것입니다.
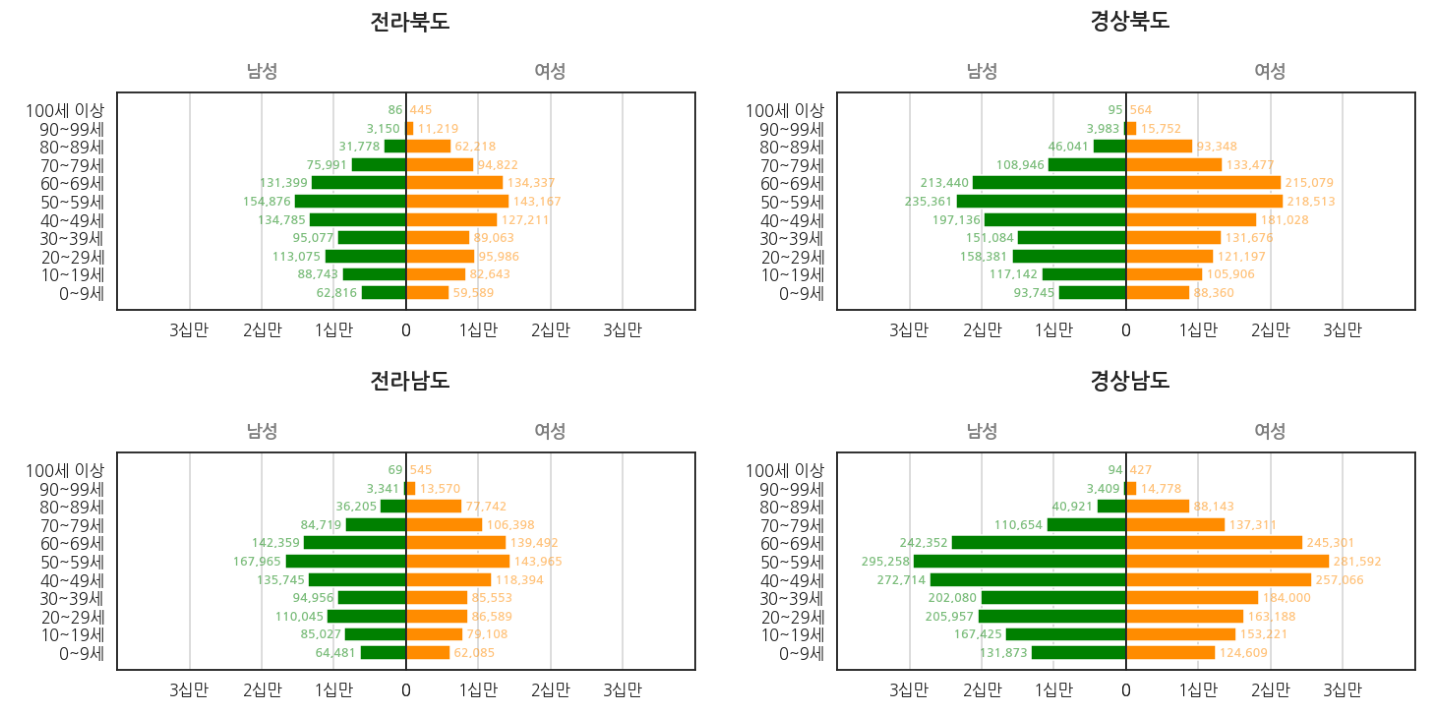
2. 데이터 준비
- 모두의 데이터 분석 with 파이썬에는 인구 데이터를 내려받아 분포를 bar plot으로 표현하는 내용이 있습니다.
- 같은 데이터를 조금 더 깔끔하게, 조금 체계적으로 만들어 보겠습니다.
2.1. 데이터 다운로드
아래와 같이 주민등록 인구 및 세대현황자료에서 csv 파일을 다운받습니다.
주피터 노트북을 켜고 데이터 분석을 준비합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from copy import deepcopy
# 시각화 설정
sns.set_context("talk")
sns.set_style("white")
# Linux 한글 사용 설정
plt.rcParams['font.family']=['NanumGothic', 'sans-serif']
plt.rcParams['axes.unicode_minus'] = False
2.2. 데이터 전처리
다운받은 파일을 파이썬으로 열어봅니다.
1
2df_popkr = pd.read_csv("202108_202108_연령별인구현황_월간.csv", encoding="euc-kr")
df_popkr.head()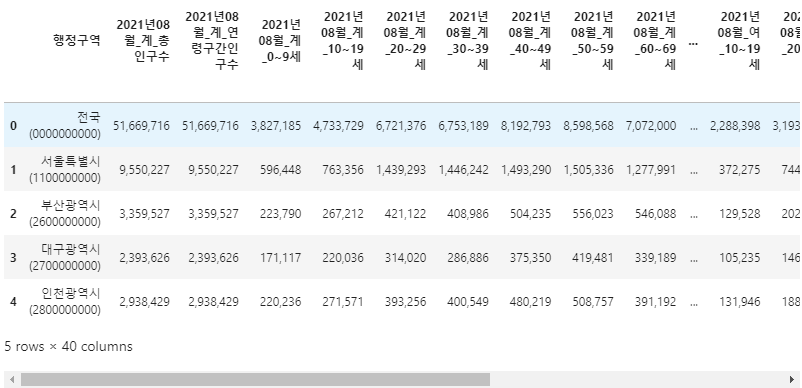
연령대와 성별이 column으로 정리되어 있고 행정구역들이 첫번째 column에 나열되어 있습니다.
분석하기에 좋은 모양은 아닙니다. 전처리를 들어갑니다.
2.2.1. 데이터 내용 정리
행정구역에서 불필요한 번호를 떼어냅니다.
1
2df_popkr["행정구역"] = df_popkr["행정구역"].str.split("(").str[0]
df_popkr.head()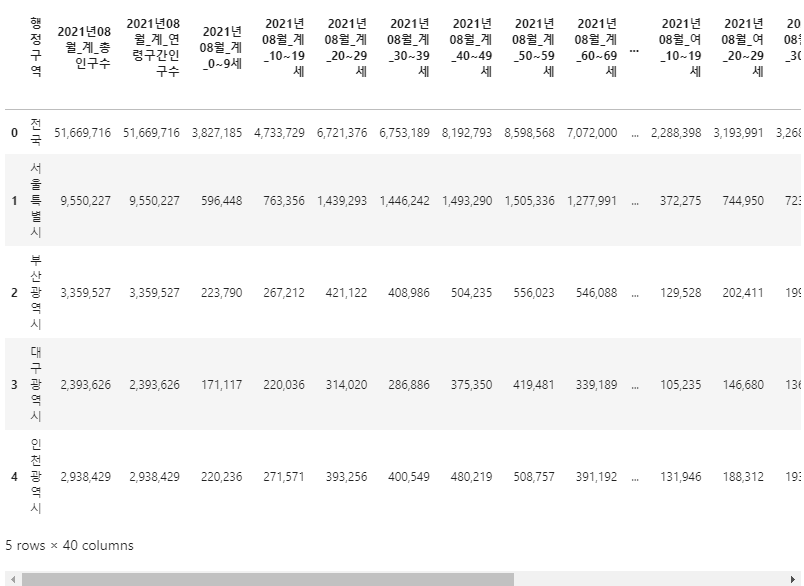
행정구역에서 번호가 떨어진 뒤에 빈 칸이 붙어 있습니다.
숫자들 사이에는 자리수를 표현하는 쉼표(,)가 붙어 있습니다.
df.replace()로 처리합니다.1
2
3df_popkr.replace(",", "", regex=True, inplace=True)
df_popkr.replace(" ", "", regex=True, inplace=True)
df_popkr.head()
2.2.2. 성별 분리
- 남성과 여성 데이터를 따로 그릴 것입니다. 데이터부터 분리합니다.
- 먼저 남성 데이터를 정리합니다.
- 컬럼명에 “남”이 있는 것들을 골라냅니다.
- 그 중에서도 불필요한 내용을 제거하기 위해 “세”가 있는 것만 또 따로 분리합니다.
1
2df_popkrM = df_popkr.filter(like="남").filter(like="세")
df_popkrM.head()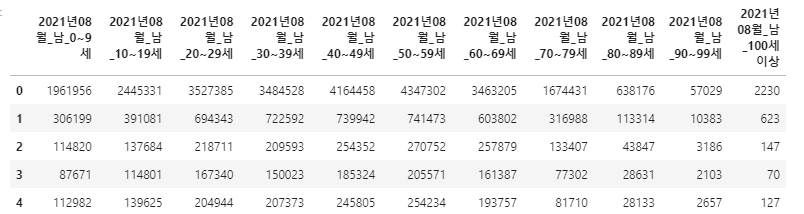
2.2.3. 행-열 전환
- 데이터를 편하게 다루려면 열에 지역명, 행에 나이대를 놓는 것이 좋습니다.
df.T로 행과 열을 바꾼 뒤df.astype(int)로 정수형으로 변환합니다.1
2
3
4df_popkrMT = df_popkrM.T
df_popkrMT.columns = df_popkr["행정구역"].values
df_popkrMT = df_popkrMT.astype(int)
df_popkrMT.head()
2.2.4. “나이”만 남기기
- 나이 정보가 index로 오긴 했지만 불필요한 정보들이 많습니다.
pd.Series.str.split()을 사용해 나이만 남깁니다.1
2
3df_popkrMT["나이"] = df_popkrMT.index.str.split("_").str[2]
df_popkrMT.reset_index(drop=True, inplace=True)
df_popkrMT
2.2.5. 여성 데이터 정리
- 같은 요령으로 여성 데이터도 정리합니다.
- 위에서 뭔가 복잡하게 한 것 같지만 코드 6줄로 정리됩니다.
1
2
3
4
5
6
7df_popkrF = df_popkr.filter(like="여").filter(like="세")
df_popkrFT = df_popkrF.T
df_popkrFT.columns = df_popkr["행정구역"].values
df_popkrFT = df_popkrFT.astype(int)
df_popkrFT["나이"] = df_popkrFT.index.str.split("_").str[2]
df_popkrFT.reset_index(drop=True, inplace=True)
df_popkrFT.head(3)
3. 데이터 시각화
- 이제 정리한 데이터를 그림으로 표현할 차례입니다.
- 글의 맨 처음에서 어떻게 그리겠다는 것을 먼저 보여드리긴 했지만 여기서 고민이 필요합니다.
- 남 vs 여구도를 어떻게 살릴지,
- 연령대간 변화율이 아닌 연령대별 데이터를 어떻게 표현할지에 대한 고민입니다.
- 성별, 연령별 인구 분포는 많이 사용하는 형식이 있습니다.
- 등을 맞대고 있는 구도로 남 vs 여를 표현합니다.
- bar plot으로 해당 구간의 데이터에 집중합니다.
3.1. Axes 제작
plt.subplots()명령으로fig(Figure)와axs(Axes)를 동시에 생성합니다.ncols=2로 bar plot이 들어갈 Axes를 두 개 만듭니다.gridspec_kw={"wspace":0}으로 Axes 사이 간격을 없앱니다.sharey=True로 두 Axes의 y 범위를 통일합니다.1
2fig, axs = plt.subplots(ncols=2, sharey=True,
figsize=(10, 5), gridspec_kw={"wspace":0})
3.2. bar plot
- 공간이 준비됐으니 데이터를 넣습니다.
ax.barh()명령으로 가로 bar plot을 그립니다.- x에 나이, y에 전국 인구 수를 넣습니다.
- 남성은 green, 여성은 darkorange로 표현합니다.
1
2
3fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")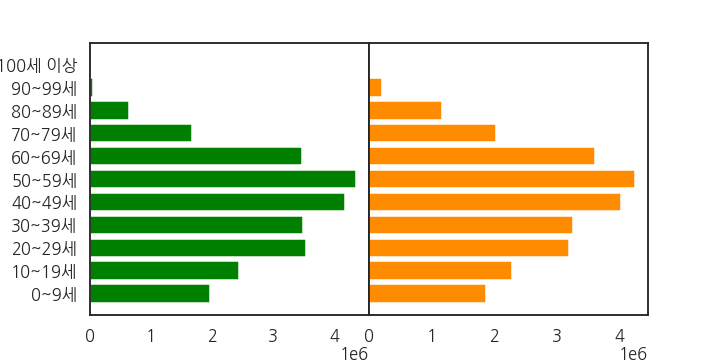
3.3. 남성 좌우 반전
- 남녀가 등을 맞대고 있도록 표현하려면 남성 데이터의 좌우를 뒤집어야 합니다.
- 데이터 범위의 최대값
xmax을 충분히 큰 수로 지정하고, - 남성은 xmax에서 0으로, 여성은 0에서 xmax로 가도록 지정합니다.
ax.set_xlim()을 사용합니다.1
2
3
4
5
6
7fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")
xmax = 4.5e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)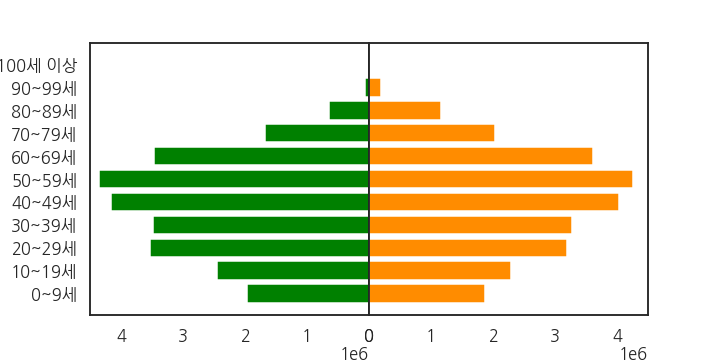
3.4. xticklabels 수정
- x축 눈금 레이블(xticklabels)이 0부터 4까지 적혀있고 1e6이라는 숫자가 함께 있습니다.
- $0 \times 10^6$ ~ $4\times 10^6$ 이라는 의미이지만 잘 읽히지 않습니다.
- $4\times 10^6$은 우리 뇌 속에서 4,000,000이 되고, 다시 4백만이 됩니다.
- 이럴 바에는 그냥 4백만이라고 써 주는게 낫습니다.
f-string과 list comprehension을 이용해 xticklabels를 수정합니다.- Axes 두 개에 똑같은 일을 해야 합니다.
for loop으로 반복시킵니다.1
2
3
4
5
6
7
8
9
10
11
12fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")
xmax = 4.5e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)
xticks = np.arange(0, xmax, 1e6)
for ax in axs:
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*1e-6)}백만" if x != 0 else "0" for x in xticks])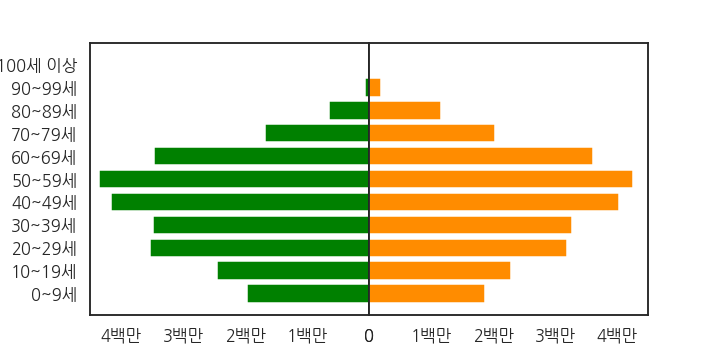
3.5. title, grid 추가
남성과 여성을 나란히 그렸으니 어디가 어디인지 적어줘야 합니다.
중앙에서 좌우로 뻗은 막대들이 언뜻 보면 비슷합니다.
정량적인 비교를 돕기 위해 grid를 추가합니다.
제목은
ax.set_title(), 눈금은ax.grid()명령입니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")
xmax = 4.5e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)
xticks = np.arange(0, xmax, 1e6)
for ax, title in zip(axs, ["남성", "여성"]):
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*1e-6)}백만" if x != 0 else "0" for x in xticks])
ax.grid(c="lightgray")
ax.set_title(title, color="gray", fontweight="bold", pad=16)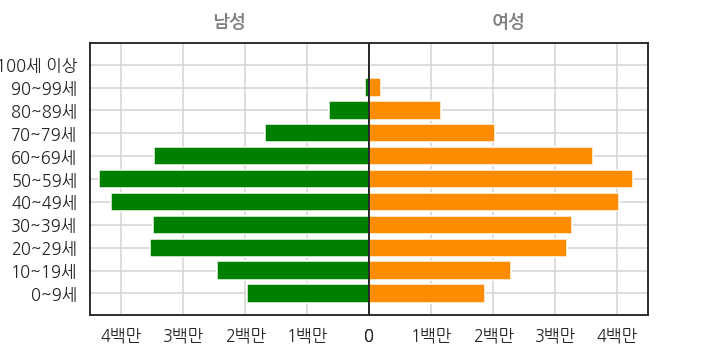
이제 남성과 여성의 차이가 조금 눈에 들어옵니다.
70대 여성은 2백만명이 넘지만 70대 남성은 2백만명이 못 됩니다.
10세 미만은 여성보다 남성이 더 많습니다.
3.6. text 추가
- grid 덕택에 조금은 읽기가 수월해졌지만 정확한 값은 보이지 않습니다.
- 숫자는 신빙성을 부여합니다. 활용성도 높아집니다.
ax.text()명령으로 글자를 넣을 수 있습니다.
그런데 어디에 넣을까요?
막대 끝에 넣으면 어떨까요? 데이터의 편차가 돋보일 것입니다.
bar plot은 Matplotlib이 patch라는 객체로 관리합니다.
ax.patches[0]이라면 맨 처음에 붙인 객체를 의미합니다.ax.patches와 for loop을 결합하면 하나씩 순회하면서 숫자를 달아봅시다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")
xmax = 4.5e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)
xticks = np.arange(0, xmax, 1e6)
for ax, title in zip(axs, ["남성", "여성"]):
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*1e-6)}백만" if x != 0 else "0" for x in xticks])
ax.grid(c="lightgray")
ax.set_title(title, color="gray", fontweight="bold", pad=16)
for ax in axs:
for i, p in enumerate(ax.patches):
w = p.get_width()
ax.text(w, i, f" {format(w, ',')} ",
fontsize="x-small", va="center", ha="right")
2중 for loop으로 Axes마다, patch마다 숫자를 달았습니다.
ax.patch에.get_width()를 적용해서 위치를 구했습니다.format()으로 천 단위마다 쉼표를 추가했고, ha=”right”로 우측 정렬을 했습니다.그런데 여성 데이터마저 우측 정렬이 되어버렸습니다.
if를 사용해 여성은 좌측 정렬을 합니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color="green")
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color="darkorange")
xmax = 6e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)
xticks = np.arange(0, xmax, 1e6)
for ax, title in zip(axs, ["남성", "여성"]):
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*1e-6)}백만" if x != 0 else "0" for x in xticks])
ax.grid(c="lightgray")
ax.set_title(title, color="gray", fontweight="bold", pad=16)
for ax in axs:
for i, p in enumerate(ax.patches):
w = p.get_width()
if ax == axs[0]:
ha = "right"
else:
ha = "left"
ax.text(w, i, f" {format(w, ',')} ",
fontsize="x-small", va="center", ha=ha)
3.7. 전체 제목 추가, 세부 수정
- 이제 거의 다 그렸습니다. 한번씩 보면서 맘에 들지 않는 부분을 수정합니다.
- 먼저 grid와 글자가 너무 난잡합니다.
ax.grid(axis="x")로 세로선만 남깁니다.- 숫자 색상에 남성과 여성에 사용한 색상을 적용합니다.
- 그리고 왼쪽은 남성, 오른쪽은 여성이지만 이게 어디 데이터인지가 없네요.
fig.suptitle()로 추가합니다.- 구성요소간 간격 정리를 위해
fig.tight_layout()을 사용합니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
c_M = "green"
c_F = "darkorange"
axs[0].barh(df_popkrMT["나이"], df_popkrMT["전국"], color=c_M)
axs[1].barh(df_popkrFT["나이"], df_popkrFT["전국"], color=c_F)
xmax = 6e6
axs[0].set_xlim(xmax, 0)
axs[1].set_xlim(0, xmax)
xticks = np.arange(0, xmax, 1e6)
for ax, title in zip(axs, ["남성", "여성"]):
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*1e-6)}백만" if x != 0 else "0" for x in xticks])
ax.grid(axis="x", c="lightgray")
ax.set_title(title, color="gray", fontweight="bold", pad=16)
for ax in axs:
for i, p in enumerate(ax.patches):
w = p.get_width()
if ax == axs[0]:
ha = "right"
c = c_M
else:
ha = "left"
c = c_F
ax.text(w, i, f" {format(w, ',')} ",
c=c, fontsize="x-small", va="center", ha=ha,
fontweight="bold", alpha=0.5)
fig.suptitle(" 전국", fontweight="bold")
fig.tight_layout()
3.8. 함수로 만들기
이제 조금 쓸만해진 것 같습니다.
전국 말고 시도별 데이터도 시각화하고 싶은데, 그 때마다 코드를 복붙하기 불편합니다.
함수로 만들어버립니다.
변수 이름도 조금은 더 직관적으로 만들고, 인구 수에 따라 적절히 스케일링할 수 있는 장치를 추가합니다.
지역의 인구에 따라 백만말고 십만, 만, 천명이 더 유용할 때도 있겠죠.
fig를 return해서 여차하면 추가 수정을 할 수 있도록 합니다.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45def plot_pop(loc, popmax=6e6, poptick=1e6):
fig, axs = plt.subplots(ncols=2, sharey=True, figsize=(10, 5), gridspec_kw={"wspace":0})
c_M = "green"
c_F = "darkorange"
axs[0].barh(df_popkrMT["나이"], df_popkrMT[loc], color=c_M)
axs[1].barh(df_popkrFT["나이"], df_popkrFT[loc], color=c_F)
axs[0].set_xlim(popmax, 0)
axs[1].set_xlim(0, popmax)
xticks = np.arange(0, popmax, poptick)
if poptick >= 1e6:
factor, unit = 1e-6, "백만"
elif 1e5 <= poptick < 1e6:
factor, unit = 1e-5, "십만"
elif 1e4 <= poptick < 2e5:
factor, unit = 1e-4, "만"
elif 1e3 <= poptick < 2e4:
factor, unit = 1e-3, "천"
for ax, title in zip(axs, ["남성", "여성"]):
ax.set_xticks(xticks)
ax.set_xticklabels([f"{int(x*factor)}{unit}" if x != 0 else "0" for x in xticks])
ax.grid(axis="x", c="lightgray")
ax.set_title(title, color="gray", fontweight="bold", pad=16)
for ax in axs:
for i, p in enumerate(ax.patches):
w = p.get_width()
if ax == axs[0]:
ha = "right"
c = c_M
else:
ha = "left"
c = c_F
ax.text(w, i, f" {format(w, ',')} ",
c=c, fontsize="x-small", va="center", ha=ha,
fontweight="bold", alpha=0.5)
fig.suptitle(f" {loc}", fontweight="bold")
fig.tight_layout()
return fig이 함수로 전국 인구 분포를 그려봅시다.
1
fig = plot_pop("전국")
똑같이 나왔습니다. :)
서울시를 해볼까요? 구간별 인구 단위가 십만으로 줄어듭니다.
1
fig = plot_pop("서울특별시", popmax=1e6, poptick=2e5)
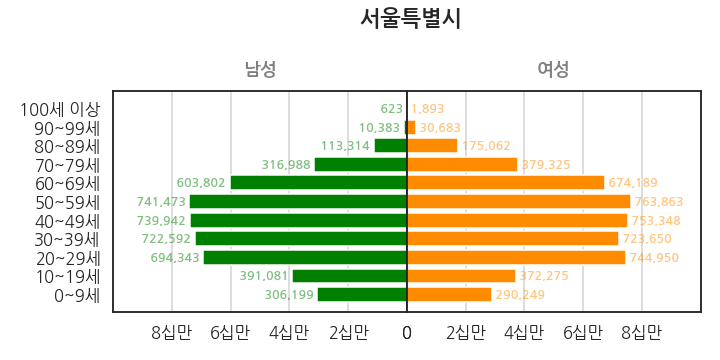
이제는 세종시 차례입니다. 구간별 인구 단위가 만단위로 줄어듭니다.
1
fig = plot_pop("세종특별자치시", popmax=1e6, poptick=2e5)
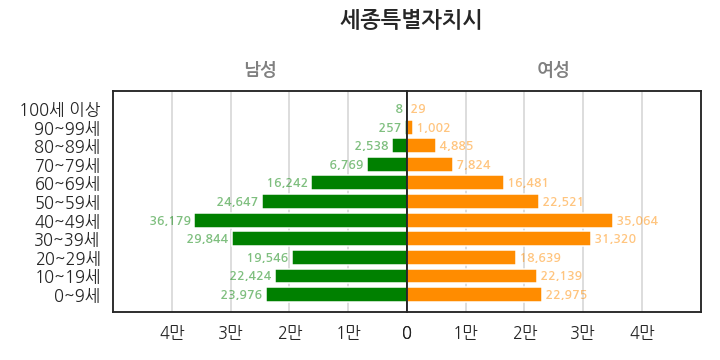
같은 요령으로 영호남과 다른 광역시도 그릴 수 있습니다.
4. 결론
- 수작업 대신 코딩을 왜 하냐는 질문에 가장 좋은 답변 중 하나는 반복 작업 처리일 것입니다.
- 수작업보다 체계적인 작업도 답변이 될 수 있을 것입니다.
- 데이터 시각화 작업을 체계적으로, 그리고 반복에 대응하는 방법은 객체지향 방식입니다.
- Matplotlib을 다루시는 많은 분들께 평안이 깃들기를 기원합니다.
